
2023-05-02_5分钟学会2023年最火的AI绘画(性能倍增:Stable Diffusion torch2.0.0 + cu118)
系列文章目录请看第一篇:
2023-03-10_5分钟学会2023世界顶级AI绘画神器Stable Diffusion(入门篇)
交流可加扣裙:四二642八九七2
在之前的版本中,一直使用的是Torch 1.x版本,并且A1111目前为止已经大概一个月没有更新webui了,在迭代的过程中出现了一堆bug导致笔者一直没用最新版,比较明显的bug比如Lora选择框不能选择None,所以如果有Lora选择框就必须选择一个Lora,这显然是不符合使用逻辑的,在github上也有一堆issue,无人解决,因为提交的一堆Pull Request无人合并,只有原作者有权限,所以有人fork了一个新的分支vladmandic的WebUI,使用了Torch 2.0
但是就在昨天(20230501),原作者终于回归了,并且发布了一个新的版本,详细如下
具体更新内容如下
Features:
- switch to torch 2.0.0 (except for AMD GPUs)
- visual improvements to custom code scripts
- add filename patterns: [clip_skip], [hasprompt<>], [batch_number], [generation_number]
- add support for saving init images in img2img, and record their hashes in infotext for reproducability
- automatically select current word when adjusting weight with ctrl+up/down
- add dropdowns for X/Y/Z plot
- setting: Stable Diffusion/Random number generator source: makes it possible to make images generated from a given manual seed consistent across different GPUs
- support Gradio’s theme API
- use TCMalloc on Linux by default; possible fix for memory leaks
- (optimization) option to remove negative conditioning at low sigma values #9177
- embed model merge metadata in .safetensors file
- extension settings backup/restore feature #9169
- add “resize by” and “resize to” tabs to img2img
- add option “keep original size” to textual inversion images preprocess
- image viewer scrolling via analog stick
- button to restore the progress from session lost / tab reload
Minor:
- gradio bumped to 3.28.1
- in extra tab, change extras “scale to” to sliders
- add labels to tool buttons to make it possible to hide them
- add tiled inference support for ScuNET
- add branch support for extension installation
- change linux installation script to insall into current directory rather than /home/username
- sort textual inversion embeddings by name (case insensitive)
- allow styles.csv to be symlinked or mounted in docker
- remove the “do not add watermark to images” option
- make selected tab configurable with UI config
- extra networks UI in now fixed height and scrollable
- add disable_tls_verify arg for use with self-signed certs
Extensions:
- Add reload callback
- add is_hr_pass field for processing
Bug Fixes:
- fix broken batch image processing on ‘Extras/Batch Process’ tab
- add “None” option to extra networks dropdowns
- fix FileExistsError for CLIP Interrogator
- fix /sdapi/v1/txt2img endpoint not working on Linux #9319
- fix disappearing live previews and progressbar during slow tasks
- fix fullscreen image view not working properly in some cases
- prevent alwayson_scripts args param resizing script_arg list when they are inserted in it
- fix prompt schedule for second order samplers
- fix image mask/composite for weird resolutions #9628
- use correct images for previews when using AND (see #9491)
- one broken image in img2img batch won’t stop all processing
- fix image orientation bug in train/preprocess
- fix Ngrok recreating tunnels every reload
- fix –realesrgan-models-path and –ldsr-models-path not working
- fix –skip-install not working
- outpainting Mk2 & Poorman should use the SAMPLE file format to save images, not GRID file format
- do not fail all Loras if some have failed to load when making a picture
感兴趣可以自行读一下更新内容,其中最重要的莫过于使用了torch 2.0.0版本,性能方面有了比较大的提升,笔者测试下来,甚至提升了将近一倍,出图时间缩小为原来的1/2,下面详细测试一下
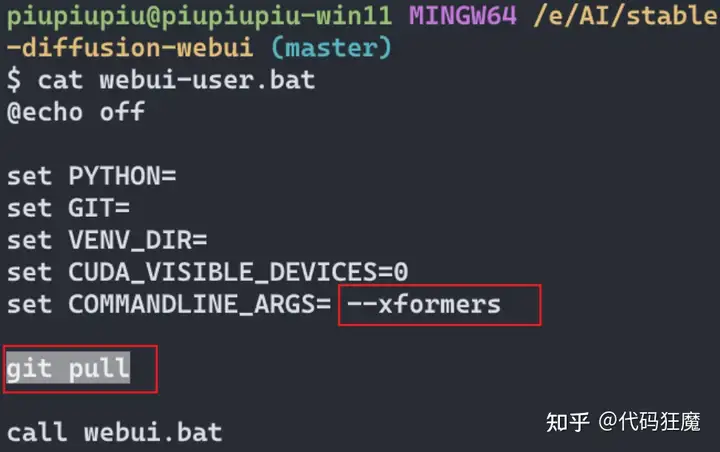
安装
建议直接克隆官方仓库即可,但是注意记得原来文件的备份,建议将所有模型等大文件单独放置一个目录,使用软连接的方式将多个WebUI链接到同一个模型文件目录上,节省硬盘空间,在Windows中,使用如下方式进行软连接
mklink /D F:AIstable-diffusion-webui-betamodels D:AIlarge_modelsmodels
mklink /D F:AIstable-diffusion-webui-stablemodels D:AIlarge_modelsmodels1、将D:AIlarge_modelsmodels目录软连接至目录F:AIstable-diffusion-webui-betamodels
2、将D:AIlarge_modelsmodels目录软连接至目录F:AIstable-diffusion-webui-stablemodels
这样beta和stable都可以使用同一个模型目录!
测试图片
- Promot
best quality,(masterpiece:1.2),photo realistic, raw photo, (fractal art:1.2),colorful,(abstract water color background:1.3), soothing tones,blue eyes,blue hair,
1 female, mature female, (koh_amberheard:0.8), looking at viewer, hanfu, ming style, <lora:hanfu_v30:0.4>
Negative prompt: easynegative,badhandv4,watermark,text,black and white photos,(worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)),
best quality,(masterpiece:1.2),photo realistic, raw photo, (fractal art:1.2),colorful,(abstract water color background:1.3), soothing tones,
1 female, mature female, (koh_amberheard:0.8), looking at viewer, __my\hanfu4__, (folk dance pose),"
Steps: 12, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 902893637, Size: 512x768, Model hash: 4d91c4c217, Model: lyriel_v15, Denoising strength: 0.5, ENSD: 31337, Hires upscale: 2, Hires steps: 10, Hires upscaler: R-ESRGAN 4x+ Anime6B- 模型:lyriel_v15
- VAE:vae-ft-mse-840000-ema-pruned
图片如下

测试方法
将以上图片在旧版本和新版本分别运行三次,观察内存和时间用量,取最大最小和平均值,基本测试后在测试放大4K,使用,使用ControNet的tile模型加上Tiled DIffusion放大的到4K,这个过程等待比较久,就测试一次了,放大4K参数如下,所有参数都在下面文本中,这里就不再截图赘述
(half portrait:1.3),
best quality,(masterpiece:1.2),photo realistic, raw photo, (fractal art:1.2),colorful,(abstract water color background:1.3), soothing tones,blue eyes,blue hair,
1 female, mature female, (koh_amberheard:0.8), looking at viewer, hanfu, ming style, <lora:hanfu_v30:0.4>
Negative prompt: easynegative,badhandv4,watermark,text,black and white photos,(worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)),
best quality,(masterpiece:1.2),photo realistic, raw photo, (fractal art:1.2),colorful,(abstract water color background:1.3), soothing tones,
1 female, mature female, (koh_amberheard:0.8), looking at viewer, __my\hanfu4__, (folk dance pose),"
Steps: 12, Sampler: Euler a, CFG scale: 7, Seed: 902893637, Size: 2048x3072, Model hash: 4d91c4c217, Model: lyriel_v15, Denoising strength: 0.75, ENSD: 31337, Mask blur: 4, Tiled Diffusion upscaler: R-ESRGAN 4x+ Anime6B, Tiled Diffusion scale factor: 2, Tiled Diffusion: "{'Method': 'Mixture of Diffusers', 'Latent tile width': 128, 'Latent tile height': 128, 'Overlap': 16, 'Tile batch size': 8, 'Upscaler': 'R-ESRGAN 4x+ Anime6B', 'Scale factor': 2, 'Keep input size': True}", ControlNet-0 Enabled: True, ControlNet-0 Module: none, ControlNet-0 Model: control_v11f1e_sd15_tile [a371b31b], ControlNet-0 Weight: 1, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
Used embeddings: easynegative [119b], badhandv4 [dba1], koh_amberheard [23d3]
Used embeddings: koh_amberheard [23d3]后面发现这里少了个重要参数,Encoder Tile Size和Decoder Tile Size,这两个值分别是1536和96,根据事情情况设定,太大可能会爆显存。
这里贴一下硬件参数:
- 处理器 AMD Ryzen 5 2600X Six-Core Processor 3.60 GHz
- 机带 RAM 32.0 GB
- 显卡:4070TI
旧版本:torch1.13.1+cu117+xformers0.0.16
- 第一次测试结果
Time taken: 33.91sTorch active/reserved: 4929/6432 MiB, Sys VRAM: 8722/12282 MiB (71.01%)- 第二次测试结果i
Time taken: 27.76sTorch active/reserved: 4925/6428 MiB, Sys VRAM: 8726/12282 MiB (71.05%)- 第三次测试结果
Time taken: 27.82sTorch active/reserved: 4925/6428 MiB, Sys VRAM: 8734/12282 MiB (71.11%)- 4K高清修复
Time taken: 1m 58.12sTorch active/reserved: 3303/3732 MiB, Sys VRAM: 11519/12282 MiB (93.79%)新版本:torch2.0.0.+cu118+xformers0.0.18
- 第一次测试结果
Time taken: 21.47sTorch active/reserved: 5373/8704 MiB, Sys VRAM: 12257/12282 MiB (99.8%)- 第二次测试结果i
Time taken: 15.98sTorch active/reserved: 5368/8704 MiB, Sys VRAM: 12127/12282 MiB (98.74%)- 第三次测试结果
Time taken: 15.81sTorch active/reserved: 5368/8704 MiB, Sys VRAM: 11990/12282 MiB (97.62%)- 4K高清修复
Time taken: 1m 17.42sTorch active/reserved: 6362/9418 MiB, Sys VRAM: 12282/12282 MiB (100.0%)结论
文生图+高清修复
- 时间
| 版本 | 第一次 | 第二次 | 第三次 |
|---|---|---|---|
| 旧版本:torch1.13.1+cu117+xformers0.0.16 | 33.91 | 27.76 | 27.82 |
| 新版本:torch2.0.0.+cu118+xformers0.0.18 | 21.47 | 15.98 | 15.81 |
结论:第一次由于需要加载模型等初始化操作,所以用时比第二、三次久一些,第二次和第三次基本差不多,所以就以第三次作为参考,整体新版本比旧版本速度快43%左右
- 显存
| 版本 | 第一次 | 第二次 | 第三次 |
|---|---|---|---|
| 旧版本:torch1.13.1+cu117+xformers0.0.16 | 71.01% | 71.05% | 71.11% |
| 新版本:torch2.0.0.+cu118+xformers0.0.18 | 99.8% | 98.74% | 97.62% |
结论:可以看到显存使用上其实新版本使用得更多,不清楚新版本是不是以空间换时间
的做法,这里没有大量数据验证,只能得出一个简单结论,新版可能是显存能用多少用多少,具体需要更多验证。
4K高清修复
- 时间
| 版本 | 第一次 |
|---|---|
| 旧版本:torch1.13.1+cu117+xformers0.0.16 | 1m 58.12s |
| 新版本:torch2.0.0.+cu118+xformers0.0.18 | 1m 17.42s |
结论:新版比旧版快约34%,(后面又测试了一次,第二次运行应该还要快一些)
- 显存
| 版本 | 第一次 |
|---|---|
| 旧版本:torch1.13.1+cu117+xformers0.0.16 | 93.79% |
| 新版本:torch2.0.0.+cu118+xformers0.0.18 | 100.0% |
结论:可参考文生图+高清修复的简单结论
![图片[3]-5分钟系列:5分钟学会2023年最火的AI绘画(性能倍增:Stable Diffusion torch2.0.0 + cu118)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[4]-5分钟系列:5分钟学会2023年最火的AI绘画(性能倍增:Stable Diffusion torch2.0.0 + cu118)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏








暂无评论内容