
- 注意以下一些内容可能需要魔法上网
- 没特别说明,以下内容只适用英伟达显卡
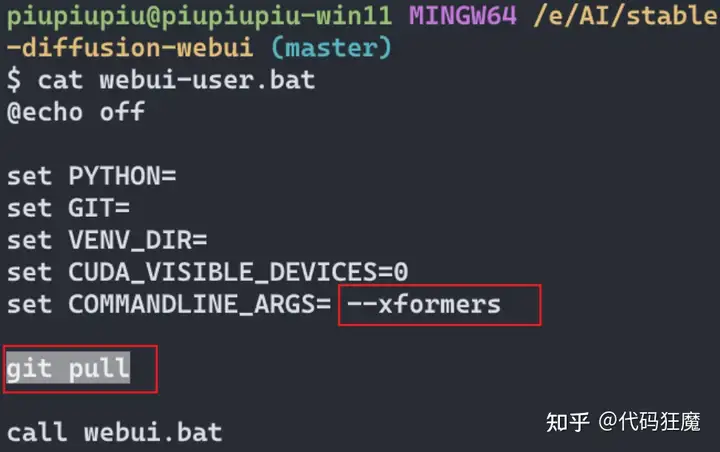
启动姿势
学会下面的启动方式,可以更好的使用,在启动的时候可在webui-user.bat中
- 加入git pull每次都自动去仓库拉取代码保持最新
- 加入启动参数 –xformers,开启xformers提高性能
- 另外注意有个参数
set
CUDA
_VISIBLE_DEVICES=0
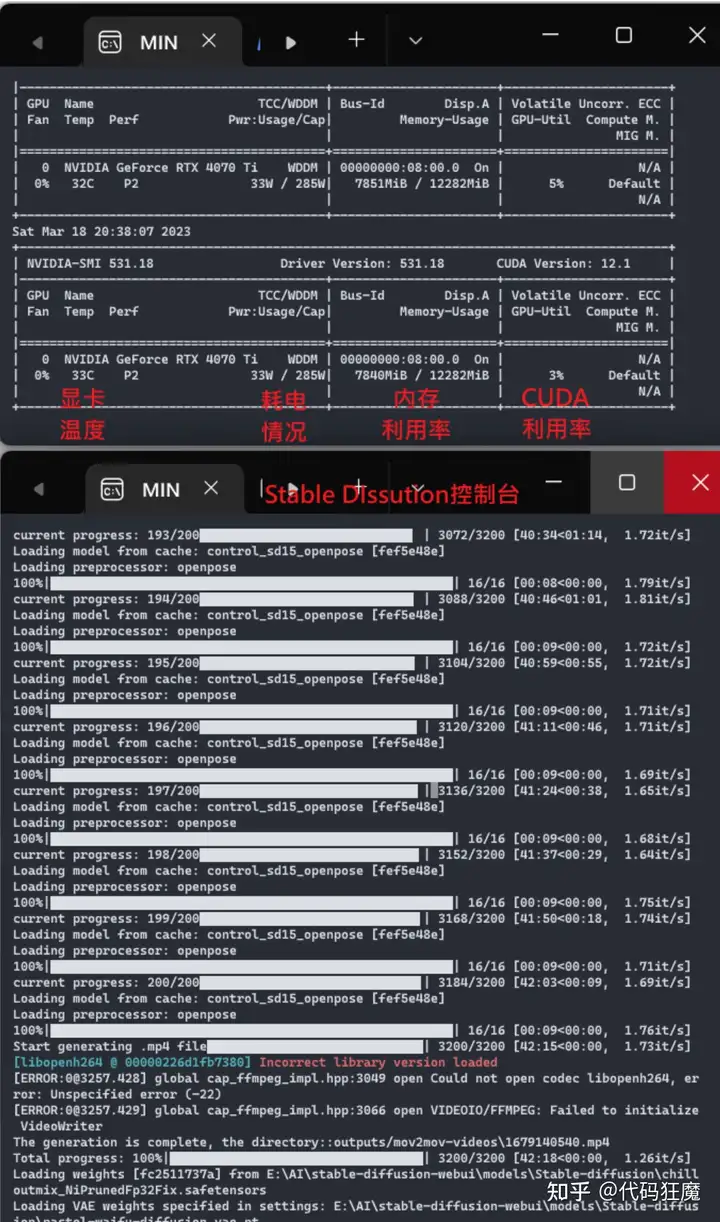
启动后保持窗口在前台可实时关注运行情况,有时候WebUI看不到的信息可以在控制台查看日志信息,另外建议新开一个git bash窗口用于查看显卡的实时信息
while true;
do
nvidia-smi | head -n 12
sleep 1
done
我一般需要看当前显卡温度、功耗多少瓦、内存使用情况、CUDA核心利用率情况,整体运行信息如下所示
汉化和关键词自动补全
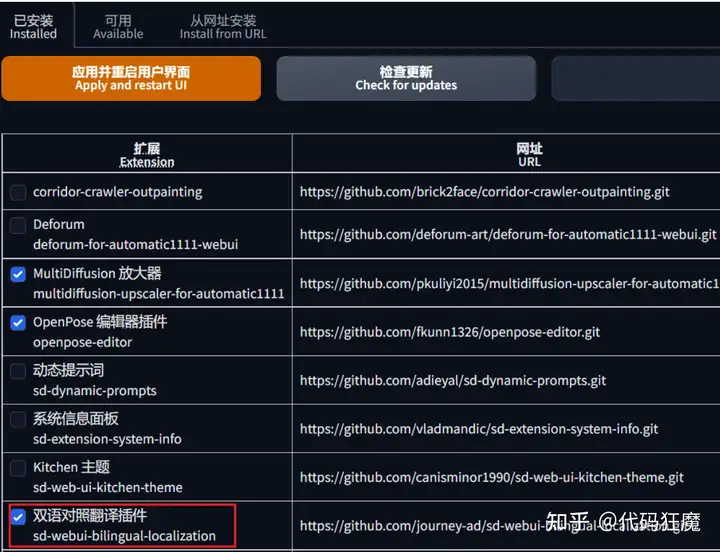
首先强烈建议安装个汉化扩展,便于理解参数,不然全是英文看着头疼,当然必须克服英文,因为文生图所用到的关键词全是英文的:(((lll¬ω¬),启动Stable Diffusion(如果不知道是什么,可以看该系类的第一篇)后,找到Extensions,点击Available,然后找到一个插件叫做
- sd-webui-bilingual-localization
下载安装它,如下图所示,因为我安装过了,因此下面的截图都是安装之后的
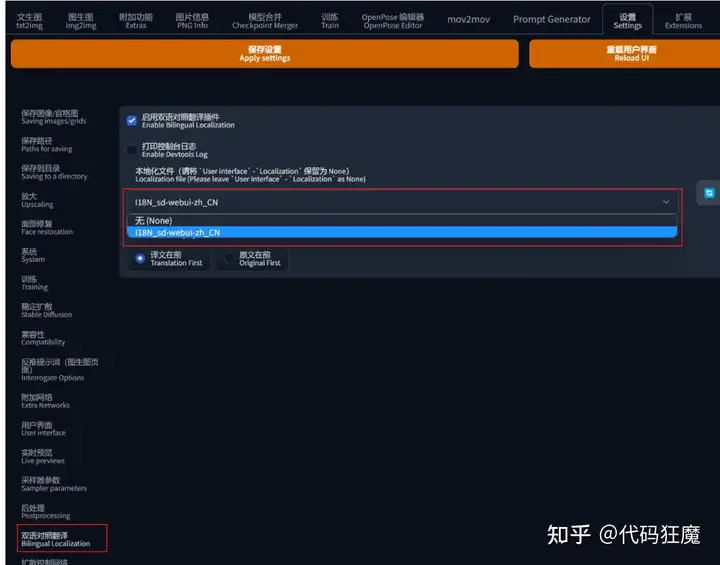
下载好后,找到Settings > BilingualLocalization > Localization file,选择I18N_sd-webui-zh_CN,如下图所示,另外需要注意要将 User interface –Localization 保留为 None,下图中也说明了
另外需要注意一点,作者的仓库代码中不提供I18N_sd-webui-zh_CN.json文件,需要在下面的链接进行下载
下载好后找了一圈也没说明放到哪里,最后在Stable DIffusion的安装目录中找到了 stable-diffusion-webui
/localizations目录,将下载好的文件放到该目录后重启WebUI即可
重启好后你的界面应该就和我的一样了,双语对照还是很有帮助的,便于翻英文资料的时候带入(因为我的是Windows11暗色模式,因此浏览器自适应暗色主题了,你的应该是白色的)
另外再建议安装一个插件:
- tag-autocomplete
它可以自动补充tag,最开始我看一些整合包装出来就带这个插件,效果可以,自动补全提示词,如下图所示
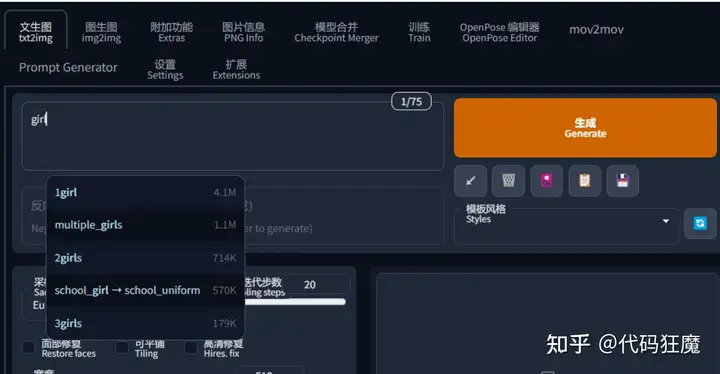
该插件目前没有集成在Stable Diffusion中,需要选择Install from URL,填入下面的URL后重启WebUI即可,此处不再赘述
另外建议在
模型(CheckPoint)下载
之前的章节中提到过如何下载模型,此处简要说明下,去下面地址下载chilloutmix_NiPrunedFp32Fix.safetensors文件后放到stable-diffusion-webui/models/Stable-diffusion目录下
然后在首页刷新,如果能看到刚才的文件说明下载成功
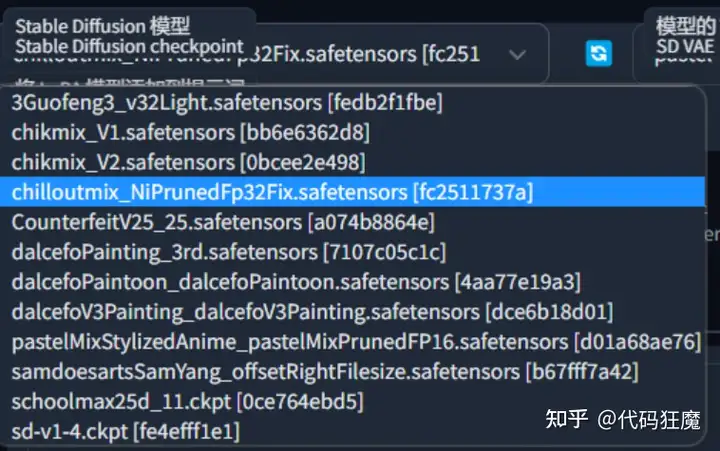
这里需要解释下,模型文件一般是.safetensors文件或者.ckpt文件,目前建议使用.safetensors文件,因为
- 文件更小
- 安全性更高
另外注意. safetensors
格式的文件也有可能是Lora,不一定是CheckPoint,后续讲到的时候在细说。
文生图
概述
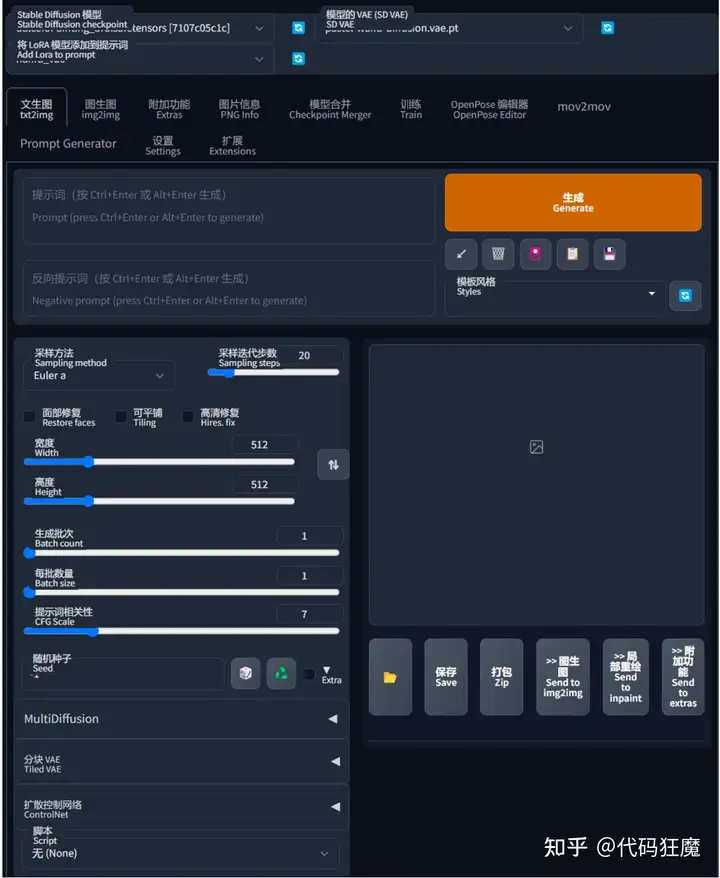
文生图故名思意就是通过文字说明生成图片,文字可以是关键词的堆积(可以理解成淘宝商品名)或者一句完整的描述,关键词也叫tag或者prompt,也有人称为咒语hh,后文都称tag,学习最好的办法就是先模仿,先看看别人是怎么写tag的,到civitai上随便找一张图
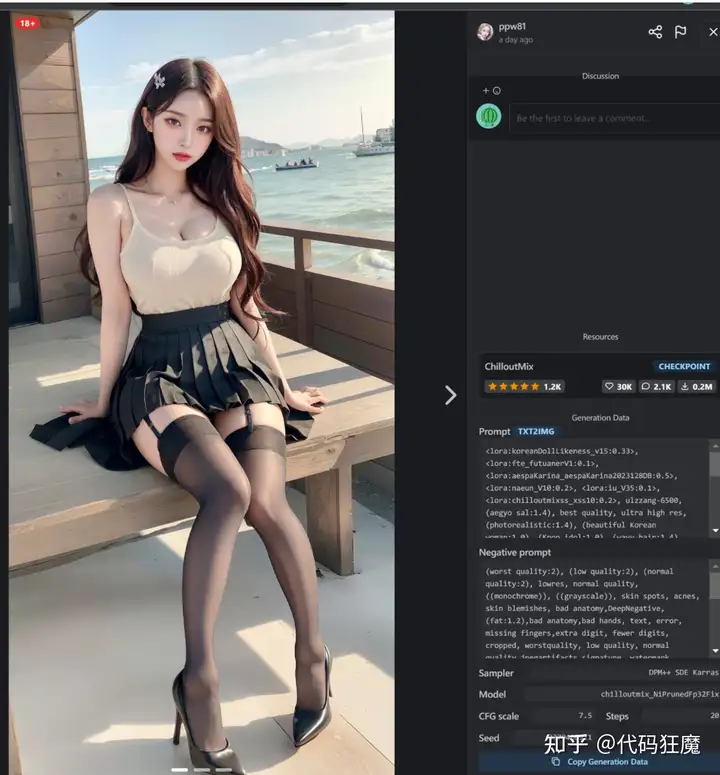
粘贴后点击三角自动解析参数
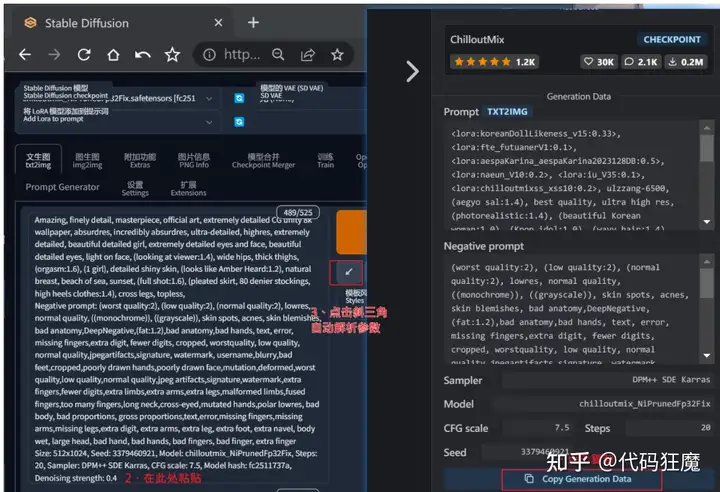
点击生成后看看图片和别人是否一致,生成的图大概率不一致
- 因为它 引用的一些Lora可能本地不存在
- 每种显卡显存可能不一致,计算不一致等可能导致不一样(猜想)
有时候即使所有参数都一样生成的图都不能完全一样,不用过于纠结,基本是一样的,由于上面的案列生成了18R+的图此处稍微调整了下tag组以后生成如下的图,有点梦幻的小姐姐,可以看到并不是很完美,比如鞋子的顺序、凳子居然是一直脚在支撑,在平时生成图的过程中经常是不完美的,经常有这样或者那样的问题,网上别人晒出来的或许是批量生成了好多张然后挑选了最好的几张,这是个正常现象。

生成图片的下面包含了本张图片的所有信息,包括正负tag,分辨率、算法、高分修复、部署等等,如果要分享给别人,把这张图本身(不要做其他任何处理)分享给别人是最好的办法,这些信息都会包含在这张图片的注释信息中。
上面这张图生成的信息如下文本
<lora:koreanDollLikeness_v15:0.33>, <lora:fte_futuanerV1:0.1>, <lora:aespaKarina_aespaKarina2023128DB:0.5>, <lora:naeun_V10:0.2>, <lora:iu_V35:0.1>, <lora:chilloutmixss_xss10:0.2>, ulzzang-6500, (aegyo sal:1.4), best quality, ultra high res, (photorealistic:1.4), (beautiful Korean woman:1.0), (Kpop idol:1.0), (wavy hair:1.4), (bangs:1.4), masterpiece, illustration, an extremely delicate and beautiful, extremely detailed, CG,unity, 8k wallpaper, Amazing, finely detail, masterpiece, official art, extremely detailed CG unity 8k wallpaper, absurdres, incredibly absurdres, ultra-detailed, highres, extremely detailed, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, light on face, (looking at viewer:1.4), wide hips, thick thighs, (1 girl), detailed shiny skin, (looks like Amber Heard:1.2), natural breast, beach of sea, sunset, (full shot:1.6), (pleated skirt, 80 denier stockings, high heels clothes:1.4), cross legs
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,
skin blemishes
, bad anatomy,DeepNegative,(fat:1.2),bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,
cross-eyed
,mutated hands,polar lowres, bad body, bad proportions, gross proportions,text,error,missing fingers,
missing arms
,missing legs,extra digit, extra arms, extra leg, extra foot, extra navel, body wet, large head, bad hand, bad hands,
bad fingers
, bad finger, extra finger
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7.5, Seed: 3379460921, Face restoration: CodeFormer, Size: 512x1024, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.4, Hires upscale: 2, Hires upscaler: Latent可以看到tag非常多,可以预想如果要生成理想的图,就需要给AI描述清楚所有关键信息,包括正面和负面的
另外最后两行还包括其他信息
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7.5, Seed: 3379460921, Face restoration: CodeFormer, Size: 512x1024, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.4, Hires upscale: 2, Hires upscaler: Latent分别是
- 步数:Steps: 20
- 采样算法:Sampler: DPM++ SDE Karras,
- 提示词相关性:CFG scale: 7.5,
- 种子:Seed: 3379460921,
- 面部修复:Face restoration: CodeFormer,
- 分辨率:Size: 512×1024,
- 种子:Model hash: fc2511737a,
- 模型:Model: chilloutmix_NiPrunedFp32Fix,
- 重绘幅度:Denoising strength: 0.4,
- 高分修复倍数:Hires upscale: 2,
- 高分修复算法:Hires upscaler: Latent

Time taken: 1m 30.76sTorch active/reserved: 6992/10794 MiB, Sys VRAM: 12282/12282 MiB (100.0%)表示生成这张图用了1m30.76s,不慢但绝对说不上快,笔者4070ti 12G显存的显卡也需要这么久,主要是开了高分修复,后续会详细讲到。
在看看Stable Difusstion控制台,可以看到其实一些Lora并没有找到,这也是生成的图和原图不一致的原因
Couldn't find Lora with name fte_futuanerV1
Couldn't find Lora with name aespaKarina_aespaKarina2023128DB
Couldn't find Lora with name naeun_V10
Couldn't find Lora with name iu_V35注意下文中如果没有特殊说明,均是采用该tag进行示例
文生图所有参数
下面将介绍文生图板块所有的参数,因为写tag本身可以称之为关键词工程学,后续会详细说明,此处先把所有参数过一遍
文生图所有参数如下所示,都有双语标注,此处就不再赘述了,下面重点说明每个参数对造图的影响
采样方法
Sampling Method采样方法,通过求解函数f(x)得到分布p(x)的期望值。Stable Diffusion提供了多种采样方法以适配众多特定的应用场景。没有绝对完美的采样方法,在使用时候可以多测试一下几种采样方法,只要输出结果合适就可以了。
- a :富有创造力,不同步数可以生产出不同的图片, 超过30~40步基本就没什么增益效果了
- Euler:最最常见基础的算法,最简单的,也是最快的
- DDIM
- :收敛快,一般20步就差不多了
- LMS
- :eular的延伸算法,相对更稳定一点,30步就比较稳定了
- PLMS:再改进一点LMS
- DPM2:DDIM的一种改进版,它的速度大约是 DDIM 的两倍
下图为不同采样方法在20步时的对比图,一般真人生成笔者都采用前缀是DMP++的几个,采样方法没有绝对,在一种采样方法效果不好的时候可以尝试另外一种

采样迭代步数
AI绘画的原理就是先随机生成一张噪声图片,然后一步一步向正负tag语义靠拢,迭代步数就是告诉AI,这样的步骤需要多少次,步骤越多,每一步移动越小也越精确。同时也成比例增加生成图像所需要的时间,大部分采样器超过50步后意义就不大了,一般设置为20,如果效果不佳再往上调,最多到50
一般在描述显卡性能时会说一秒多少步(it/s),或者倒数,多少秒一步(s/it),前者是越大约好,后者越小越好,下图是用我们上面的关键词,步数分贝设置1,2,3,5,10,15,20,30,50,80后的对比,采样方法使用的是DPM++ SDE Karras

不知道为什么步数越高,衣服越少,可能是显卡太热<<大雾
面部修复
使用模型,对生成图片的人物面部(主要是三次元真人、二次元也有一定质量提高)进行修复,让人脸更像真人的人脸,具体设定在【设置】- 【面部修复】
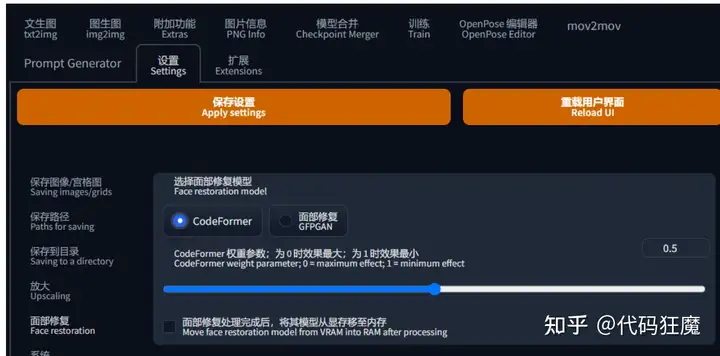
- CodeFormer 和 GFPGAN ,至于那个更好,这个不好说,这个和模型相关,基本没改过,后文没有特殊说明,都使用CodeFormer
- CodeFormer权重参数:为0时效果最大,为1时效果最小,建议从0.5开始,左右尝试,找到自己喜欢的设置。
可平铺(Tiling)
生成可以往上下左右连续拼接的图像,比如你家地上的瓷砖,主要用来生成贴图,一般不勾选,勾选后生成的图可能是这样的

高分修复
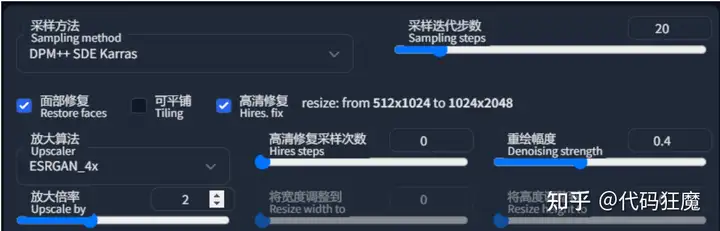
文生图在高分辨率下(1024 x 1024)会生成非常怪异的图像。而此插件这使得AI先在较低的分辨率下部分渲染你的图片,再通过算法提高图片到高分辨率,然后在高分辨率下再添加细节。
- 放大算法:如果不知道选什么,一般无脑选ESRGAN_4x、
- 高清修复采样次数:类比采样迭代步数理解,0表示沿用原来的步数
- 重绘幅度:放大后修改细节的程度,从0到1,数值越大,AI创意就越多,也就越偏离原图。
- 放大倍率:放大倍数,在原有宽度和长度上放大几倍,注意这个拉高需要更高的显存
如果原图是512 x 1024,开了高分修复后则会变成1024 x 2048,可以看到上方有类似提示
resize: from 512x1024 to 1024x2048一般建议先生成小图,在小图中找到合适的图后在开高分修复生成大图,提高速度,开高分修复会明显感受到造图速度变慢,下图为造图信息对比
- 不开高分:用时13.99s 、文件大小812K、显存占用比率49.36%
- 两倍高分:用时1m 37.31s 、文件大小3.26MB、显存占用比率100%
- 三倍高分:直接爆显存:OutOfMemoryError: CUDA out of memory
可以看下对比还是很明显的,在眼睛、头发、嘴巴、耳朵等细节上都明显更清晰

下图为两张图实际分辨率对比
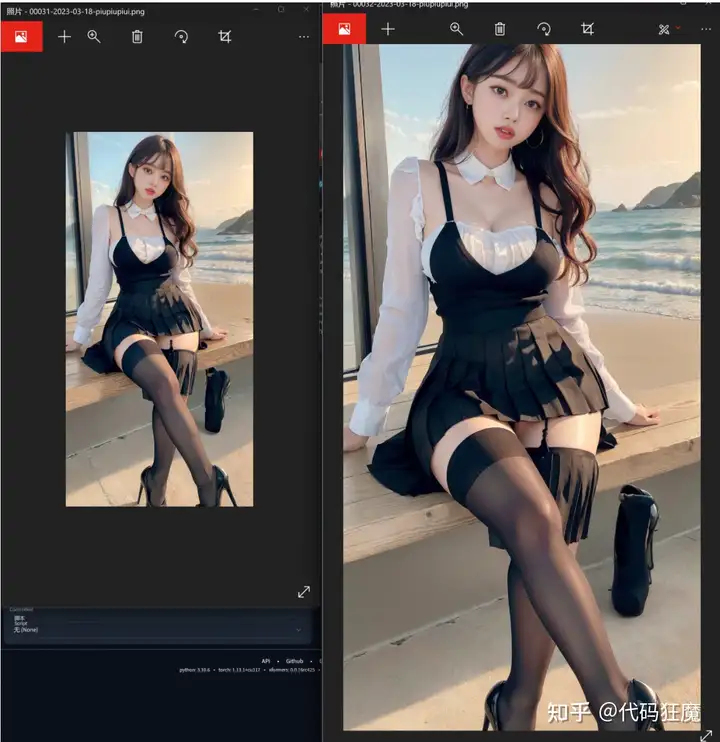
既然12G显存高分修复都爆显存,是否说明目前的主流显卡都无法造高清2K、4K大图了呢?实际上也有大佬做了碎片化高清修复的插件,大致原理是将图切碎,然后每一部分在单独重绘,最后合成一张大图,用碎片化的方式降低显存占用,这款插件叫做MultiDiffusion ,后续系列会详细说明
生成批次
同样的配置,运行多少次,即批次
每批数量
一个批次中,生成几张图片,增大该值需要考虑显存是否满足,如果显存不足和增加批次即可,生成的总的数量=生成批次*每批数量,那么4批次,每批1张和1批次,每批4张同样最后都是四张最终有什么区别呢,我们下面对比试验下(注意每张的种子是不一样的,不会生成四张一模一样的,种子后续会说明,一般采用批次多张生成然后选图)
- 4批次,每批1张一共4张,看下性能信息:Time taken: 55.01s Torch active/reserved: 3661/4462 MiB, Sys VRAM: 6766/12282 MiB (55.09%)

- 1批次,每批4张一共4张,看下性能信息:Time taken: 54.99s Torch active/reserved: 4746/11084 MiB, Sys VRAM: 12282/12282 MiB (100.0%)

明显可以可到每批张数越多越耗费显存,建议批次增加,最终生成的图其实差别不大,几乎一致。
宽度与高度
单位是像素,适当增加尺寸,AI会试图填充更多的细节进来,非常小的尺寸(低于256X256),会让AI没地方发挥,会导致图像质量下降,非常高的尺寸(大于1024X1024),会让AI乱发挥,会导致图像质量下降,增加尺寸需要更大的显存。4GB显存最大应该是1280X1280(极限)
因为常见的模型基本都是在512×512和768×768的基础上训练,分辨率过高,图片质量会随着分辨率的提高而变差,一般1024 x 1024以上尺寸AI就会造出各种鬼畜图,如果模型明确某些分辨率最优,请遵照模型的要求,比如3DKX系列模型就是明确推荐图片分辨率为1152 x 768。
如果你确实想生成高分辨率图像,请使用高分修复
- 这是通过之前的提示词,用128 * 256分辨率生成的图

- 这是通过之前的提示词,用1280*1280,似乎还好,双倍快乐

下面是1680 * 1680 生成的图,已经不知所云了

提示词相关性
图像与tag的匹配程度,增加这个值将导致图像更接近你的提示,但过高会让图像色彩过于饱和,太高后在一定程度上降低了图像质量。可以适当增加采样步骤来抵消画质的劣化,一般在5~15之间为好,7,9,12是3个常见的设置值。
下图为提示词相关性分别为1,2,3,5,9,12,15,20,30的对比图,采样步数均为20步

随机种子
之前提到,AI绘画的原理是,先随机出一个噪声图片,因为计算机世界里不存在真随机,同一模型和所有参数都一致的情况下相同的种子可以多次生成(几乎)相同的图像,如果某个种子在某tag下生成了很棒的图,保持种子数不变,而稍微改一点点tag,增减一点细节,一般得到的图也会不错
- 不同型号的显卡即使参数与模型完全一致,也可能会生成完全不同的图。10XX和16XX系显卡基本每种型号都会是不同的结果,20XX系和30XX系基本都可以完美复现图片
- 某些模型比如anything3.0因为模型过于混沌,图像复现性能一样很差
- 设置中有个选项参数叫ENSD( eta 噪声种子增量)这个会改变种子,有些扩展也可以实现同seed下随机微调种子,可能会造成无法复现其他人的图。
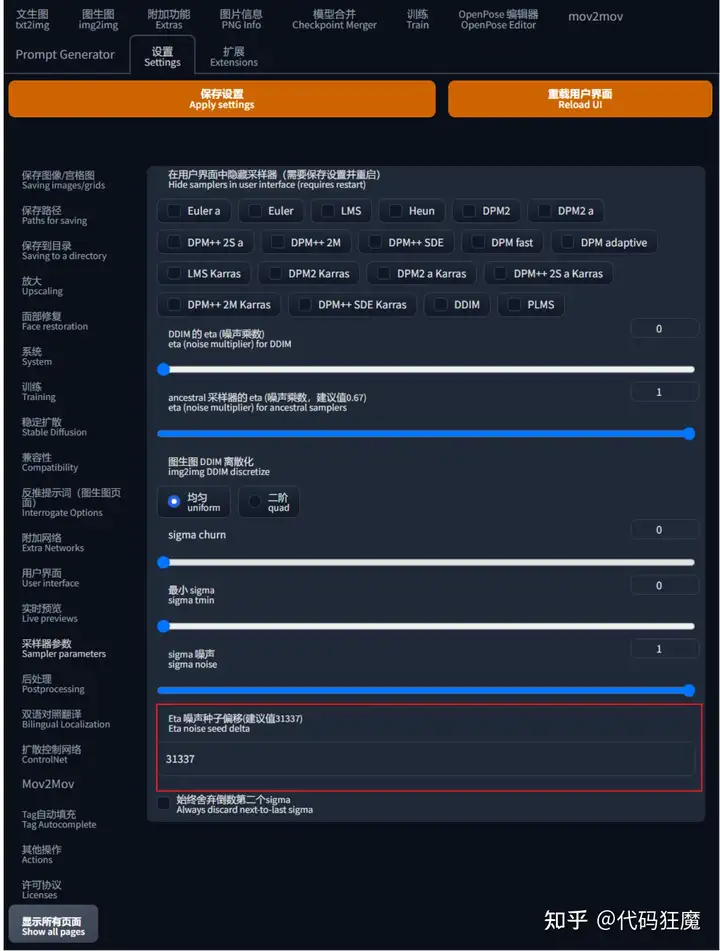
- 种子为-1表示随机,即每次生成的图可能会不一样,批量生成图的时候种子不一样所以生成的图差别比较大
- 如果找到一个比较不错的种子,可点击绿色环回三角还原最后一次出图的种子,然后点击 Extra
- 对在该种子下生成的图继续进行微调,其中主要的参数是差异强度,值在0~1之间,如果想要基于原图产生更多的变化则向1靠拢。
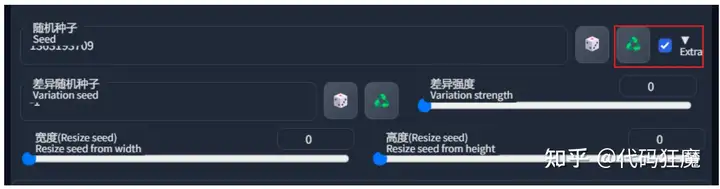
如下所示为基于种子1363193712然后差异强度分别设置0,0.1,0.2,0.3,0.5,0.8,1.0后的对比图

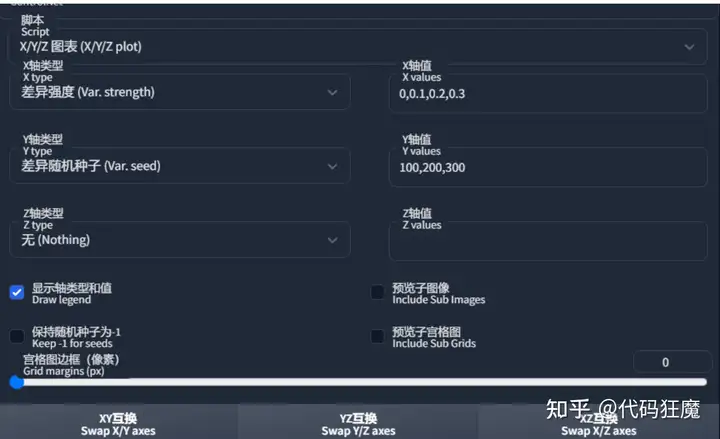
- 差异随机种子,在随机种子的基础之上在进行随机,如果将差异强度和差异随机种子做一个矩阵图,x轴表示差异随机强度,分别是0.1,0.2,0.3,y轴是差异随机种子,值分别为100,200,300,图下所示,类似于连拍图效果

脚本
脚本功能很强大,上面的一维对比图,二维矩阵图都是通过脚本实现的,下面分别说明每个脚本的作用与用法
脚本:提示词矩阵
tag用|隔开,注意
- 随机种子设置为-1
- 需要替换的词放到正负tag的末尾
- 个词前面都需要带一个|
比如在正向tag末尾添加|a|b则表示
- ab都没有
- 只有a
- 只有b
- ab都有
一共会生成四张图,如|white shirt|school uniform

脚本:从文本框或文件载入提示词
顾名思义,假设输入
red hair
blue hair
green hair出来的结果就是三张图,注意它会替覆盖掉正向tag
脚本:X/Y/Z图表
这个脚本功能很强大,上面做的对比图表都是用该脚本做的,用于展示多个参数变化的关系,其中表达式书写的规则为
- 1-5表示1, 2, 3, 4, 5
- 1-5 (+2)表示从1到5,从1开始,步进为2, 不超过5,即1,3,5;同理10-5 (-3) = 10, 7
- 0.0-1.0 [6]表示从0.0到1.0之间平均找6个数,即 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
比如上面说的连拍图效果,差异强度和差异随机种子设置如下所示:
X/Y/Z每个参数都可以从下拉框中获取不同类型的值继续替换,其中比较常用的如提示词搜索/替换(Prompt S/R),如下将X和Y的Prompt S/R分别设置为
- X:short hair,medium hair,long hair
- Y:from view,back view,full body
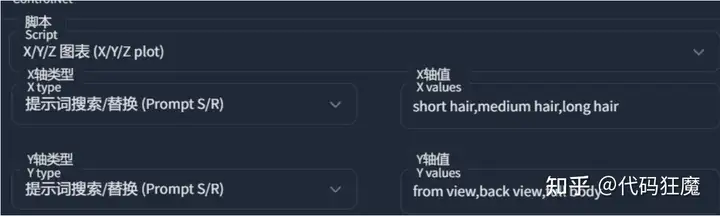
当然要反复调试下正向tag,加上一些权重才会得到比较好的结果,如下为设置好的正向tag,需要注意的是在正向tag中要包含需要替换的词,比如X轴的short hair,Y轴的from view,脚本将依次替换
<lora:koreanDollLikeness_v15:0.33>, <lora:fte_futuanerV1:0.1>, <lora:aespaKarina_aespaKarina2023128DB:0.5>, <lora:naeun_V10:0.2>, <lora:iu_V35:0.1>, <lora:chilloutmixss_xss10:0.2>, ulzzang-6500, (aegyo sal:1.4), best quality, ultra high res, (photorealistic:1.4), (beautiful Korean woman:1.0), (Kpop idol:1.0),, (bangs:1.4), masterpiece, illustration, an extremely delicate and beautiful, extremely detailed, CG,unity, 8k wallpaper, Amazing, finely detail, masterpiece, official art, extremely detailed CG unity 8k wallpaper, absurdres, incredibly absurdres, ultra-detailed, highres, extremely detailed, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, light on face, (looking at viewer:1.4), wide hips, thick thighs, (1 girl), detailed shiny skin, (looks like Amber Heard:1.2), natural breast, beach of sea, sunset,(80 denier stockings, high heels :1.4)(white shirt:1.4),(dazzling pleated skirt:1.6), cross legs,(short hair:1.6),(from view:1.6)最终结果如下,通过调整了权重后,得到比较符合语义的结果

我们试着在增加一个维度
- Z:dazzling pleated skirt,brown pleated skirt,blue dress
参数如下所示
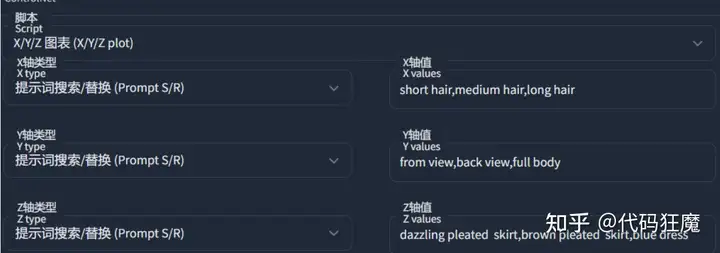
最后的效果如下所示,多了一个维度后图表变得更加复杂,高维包含了低维所有的细节

上述即是文生图的所有参数,下面讲一下提示词工程学
提示词工程学
可以看到生成上述图的提示词很多,我们单独来分析,首先是正向tag
<lora:koreanDollLikeness_v15:0.33>, <lora:fte_futuanerV1:0.1>, <lora:aespaKarina_aespaKarina2023128DB:0.5>, <lora:naeun_V10:0.2>, <lora:iu_V35:0.1>, <lora:chilloutmixss_xss10:0.2>, ulzzang-6500, (aegyo sal:1.4), best quality, ultra high res, (photorealistic:1.4), (beautiful Korean woman:1.0), (Kpop idol:1.0), (wavy hair:1.4), (bangs:1.4), masterpiece, illustration, an extremely delicate and beautiful, extremely detailed, CG,unity, 8k wallpaper, Amazing, finely detail, masterpiece, official art, extremely detailed CG unity 8k wallpaper, absurdres, incredibly absurdres, ultra-detailed, highres, extremely detailed, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, light on face, (looking at viewer:1.4), wide hips, thick thighs, (1 girl), detailed shiny skin, (looks like Amber Heard:1.2), natural breast, beach of sea, sunset, (full shot:1.6), (pleated skirt, 80 denier stockings, high heels clothes:1.4), cross legs- 其中
<lora:chilloutmixss_xss10:0.2>表示这是微调的Lora模型,如果本地没有也不会报错只是没有效果 (bangs:1.4)表示有刘海的权重是1.4倍(word)– 将权重提高 1.1 倍((word))– 将权重提高 1.21 倍(= 1.1 * 1.1),乘法的关系,以此类推,括号不宜太多[word]– 将权重降低1.1倍[[word]]– 将权重降低1.21倍,乘法的关系,以此类推,括号不宜太多(word:1.5)– 将权重提高 1.5 倍(word:0.25)– 将权重减少为原先的 25%(word)– 在提示词中使用字面意义上的 () 字符
其中前面很长一串都是描述照片本身的质量,如masterpiece,best quality, ultra high res等等,这类可以当作基础起手式,每一张都可以套用,末尾的tag才属于对主体的描述,如extremely detailed eyes and face,beach of sea, sunset等建议对每类tag使用换行符分类整理,如下
<lora:koreanDollLikeness_v15:0.33>, <lora:fte_futuanerV1:0.1>, <lora:aespaKarina_aespaKarina2023128DB:0.5>, <lora:naeun_V10:0.2>, <lora:iu_V35:0.1>, <lora:chilloutmixss_xss10:0.2>
best quality, ultra high res,masterpiece, masterpiece, illustration, an extremely delicate and beautiful, extremely detailed, CG,unity, 8k wallpaper, Amazing, finely detail, masterpiece, official art, extremely detailed CG unity 8k wallpaper, absurdres, incredibly absurdres, ultra-detailed, highres, extremely detailed
ulzzang-6500, (aegyo sal:1.4),(photorealistic:1.4), (beautiful Korean woman:1.0), (Kpop idol:1.0), (wavy hair:1.4), (bangs:1.4), beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, light on face, (looking at viewer:1.4), wide hips, thick thighs, (1 girl), detailed shiny skin, (looks like Amber Heard:1.2), natural breast, beach of sea, sunset, (full shot:1.6), (pleated skirt, 80 denier stockings, high heels clothes:1.4), cross legs分类整理后只需要对角色本身的描述进行调整,并适当加一些权重
(wavy hair:1.4), (bangs:1.4), beautiful detailed girl, extremely detailed eyes and face, (looking at viewer:1.4),(sitting on hotel bed cross leg:1.5),(pink shirt with bowknot:1.5),(package hip skirt:1.5),medium breasts, 跑了4张,如下所示

反向tag基本直接套用了,如果生成的图还有其他不需要的内容,可直接追加到反向tag中
(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, bad anatomy,DeepNegative,(fat:1.2),bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres, bad body, bad proportions, gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot, extra navel, body wet, large head, bad hand, bad hands, bad fingers, bad finger, extra finger将角色描述的tag删除,可以将提示词进行保存,保存后起名chilloutmix起手式,后续直接点击加载即可加载所有基本tag,最后在加上角色的tag即可
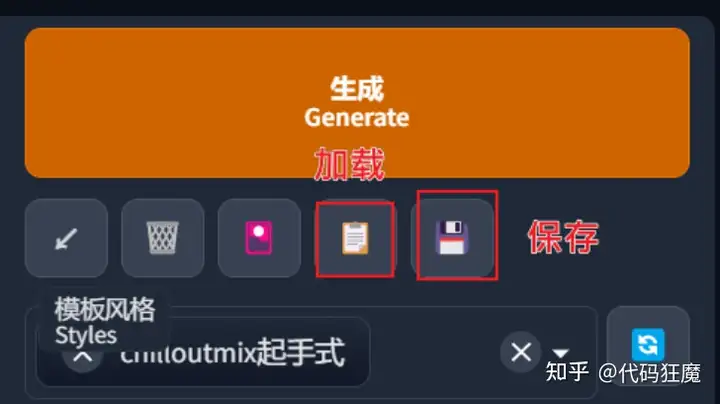
加载后比如随便写一句话,比如
a girl in dreaming forest thinking about the world,books in hand注意勾选上面部修复,采样方法选择DMP++ SDE Karras,分辨率512 * 512 随便生成4张,如下所示,可以看到基本符合描述

在根据生成的图不断增加tag去调整限定角色,tag可以是一段话,也可以是关键词堆砌,英文逗号分隔,比如
a girl in dreaming forest thinking about the world,books in hand,(red gothic dress:1.2),beautiful detail blue eyes,very long wavy blue hair, 
太多tag,甚至有些自相矛盾的tag,这样AI就不能准确识别,可以给tag适当增加权重,比如(red gothic dress:1.2),最后将需要的图挑选出来继续高清修复,这些图的不一样的只有种子,将其种子复制出来即可复刻原图
当然这这是简单的案列,可参考如下tag分类描述需要的图片:
- 主体
- 动物、人物、地点、物体等
- 质量与风格
- 照片、绘图、插画、雕塑、涂鸦等
- 环境(背景)
- 室内、室外、水上、水下、森林、月球等
- 光照
- 柔和、阴天、晴天、霓虹灯、工作室等
- 色彩
- 充满活力、柔和、高对比、单色、彩色、黑白等
- 情绪
- 稳重、平静、喧闹、开心等
- 构图
- 人像、上半身、下半身、特写、俯瞰、全身照等
我们再来尝试一下稍微复杂一点的,
a girl,busy street,(modern cyberpunk city kowloon rain neon ligh :1.6),books in hand,(night:1.2),brilliant,beautiful detail face , cat ears on head,(white maid shirt:1.4),cool,full shot,Small lip反复调试跑了好多次,最后挑选最好的8张图,记住这就是个这就是个抽卡游戏,结果在于你抽中到的种子,没出SSR就多抽几次,换换tag,换换模型和Lora,记得放平心态,不要上头,人体炼成失败是常有的事。另外分辨率比较小的时候,AI随便画两笔意思以下,导致一些面部崩坏,可以加上beautiful detail face加上权重再尝试

个人最喜欢第一张和最后一张,氛围感拉满,当然上面只是举个例子,下面例举一些比较常用的
风格
| 词 | 描述 |
|---|---|
| sketch | 可以让图片看起来像随手画的草稿 |
| lineart | 可以让线条变得很粗 |
| posing sketch, monochrome | 黑白草图 |
| rough sketch | 上了颜色的草图 |
| monochrome+lineart | 情况下一般只会让眼睛上色,强调发色后头发也可以上色 |
| monochrome, gray scale, pencil sketch lines | 做出的铅笔速写的感觉 |
利用 sketch,pastel color,lineart 的 tag 模拟一张图的绘画过程
艺术风格
| 词 | 描述 |
|---|---|
| chibi | 可以画出低头身比的效果(二头身, 三头身) |
| watercolor pencil | 可以生成彩铅画 |
| faux traditional media | 可以做出签绘的风格 |
| anime screeshot, | 可以让画面变成动画风格 |
| retro artstyle | 赛璐璐风 |
| photorealistic, painting, realistic, sketch, oil painting | 厚涂 |
| pastel color 和 sketch | 搭配会有速涂的质感 |
杂志/设定集
| 词 | 描述 |
|---|---|
| official art | 变得更加官方一点 |
| three views from front, back and side 和 costume setup materials | 可以用来生成设定图 |
| multiple views | 会出现类似设定图 |
| character sheet | 会出现设定图 |
| magazine cover | 会把背景换成杂志封面, 配合 office art 更像真实杂志(虽然字没法看) |
| magazine scan | 类似杂志内页的风格 |
| posing | 会强调有一个动作, 不至于出现混乱的动作(露出有六个手指头的手) |
| caustics | 画面向主题聚焦, 类似海报 |
常用参数: SFW
| 人物数量 | 描述 |
|---|---|
| 数量 | one boy / one girl / two boy / two girl (one_boy_one_girl 是错误的) |
| 人物画风 | 描述 |
|---|---|
| 质量提升参数 | masterpiece, best quality |
| 原神 | Genshin Impact |
| 萝莉 | female child , loli (画风差) |
视角
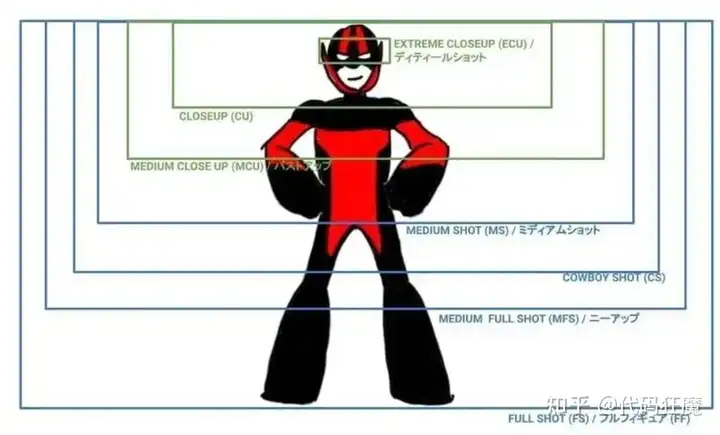
| 参数 | 解释 |
|---|---|
| extreme closeup | 脸部特写 |
| close up | 头像 |
| medium close up | 证件照 |
| medium shot | 半身 |
| cowboy shot | 无腿 |
| medium full shot | 无脚 |
| full shot | 全身 |
一些链接可速查tag
- 手抄本法术书
- Danbooru 全部 Tag 列表
- 参数法术全典
- Tag 在线协作
- NSFWTag
- AI 艺术家文档
- Novelai 关键词组合器
- Danbooru 标签超市
- AI 绘画 tag 生成器
- NovelAI tag生成器 V2.1
模型与Lora
上面只用了一种模型:chilloutmix,实际上还有很多其他值得尝试的模型与Lora,实际上还有很多其他模型,每个模型又可以套用不同的Lora进行微调,模型网站
- https:// huggingface.co/ (应该是目前最多人使用的一个分享模型的网站,不用魔法上网)
- https:// drive.google.com/drive/ folders/1vGc16Bb8CDW1piUj_5thzbsCmDFamYyt?usp=sharing (里面的很多模型是基于日本绘画师的风格训练,需魔法上网)
- https:// civitai.com/ (模型很多,各种风格的,不用魔法上网)
- https:// cyberes.github.io/stabl e-diffusion-models/ (SD模型,不用魔法上网)
- https:// rentry.co/sdmodels (模型很多,需魔法上网)
本文列举一些civitai中的常见模型,并使用文初的tag、分辨率修改为560*860造图
后续将使用该模型,然后如下常见的Lora顺序造图,想知道Lora的详细信息,直接搜索Lora的名字即可
- hanfu_v28:1.4,elegantHanfuRuqun_v10:1.4,Moxin_10:1.4,liuyifei_10:1.4,koreanDollLikeness_v15:1.4,taiwanDollLikeness_v10:1.4,japaneseDollLikeness_v10:1.4,tifaMeenow_tifaV2:1.4,wlopStyleLora_30Epochs:1.4
真人风格chilloutmix
经常霸占 C站
第一名的模型
前面的实验中一直用的该模型,此处就不再赘述,直接上Lora对比图,画出了一些上古神图,某些Lora是要和某个特定模型搭配比较好,大家可具体查看Lora说明,此处不再赘述
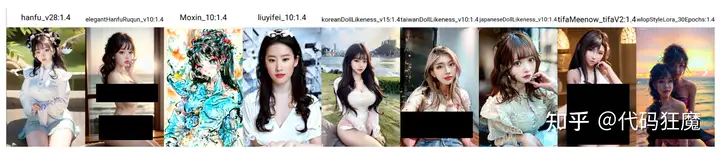
2.5D韩漫风ChikMix
2.5D风格、韩漫画风、再带VAE、广泛的NSFW内容、18R+警告
tag不很好,将就看吧
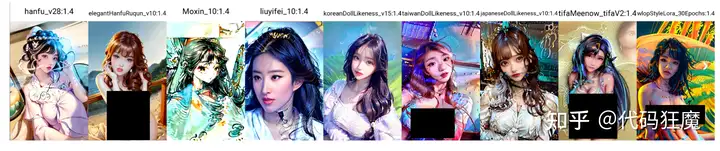
常用二次元Counterfeit
画二次元风格常用的模型
有些奇怪,可能tag不够贴合这个模型,将就看吧,需要的话自行研究tag

国风Guofeng3
一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感
国风和hanfu Lora比较搭配
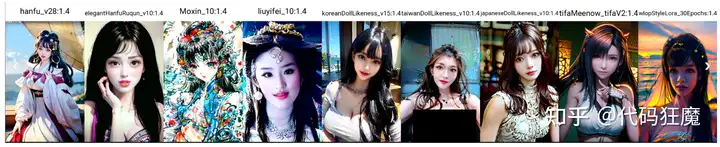
粉彩二次元风Pastel
粉彩风格模型、二次元
这种等个看起来还算可以吧

绘画风DalcefoPainting
绘画风格,这个模型生成的图很好看,笔者经常用,目前作者删库跑路了,civitai已经找不到对应模型了,但是我找到一个可以下载的地方,但是作者只留下一句话,需要模型可以邮件联系他下载,注意不要商业用途,另外作者在网站上发起了捐赠入口,用于筹集新GPU资费训练模型。
About
Do not pay just feel free to downloading my model. my models are free to use except for commercial use. only support me if you really want to do. And NEVER use my models for commercial purpose. if you have question, would you please use discord 🙂 Making ai art model. Commission is also possible. DM me or mail (dalcefo@gmail.com)
其中它有一个模型叫做
- dalcefoPainting_3rd.safetensors
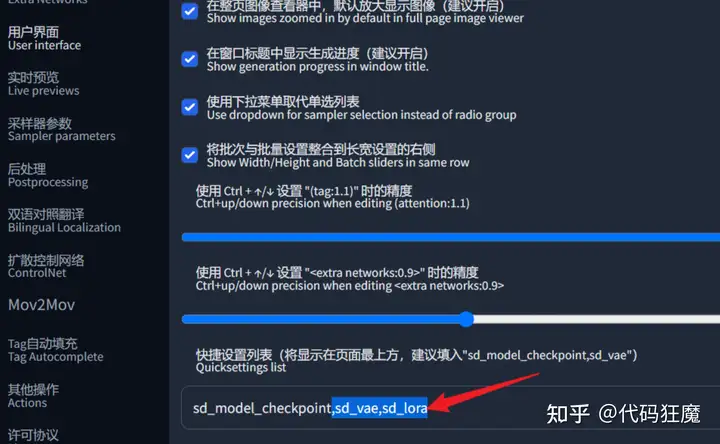
这个模型画出来的画面比较偏灰,这里需要加载一下VAE,在设置 > 用户界面 > 快捷设置列表中加入,sd_vae,
sd_lora
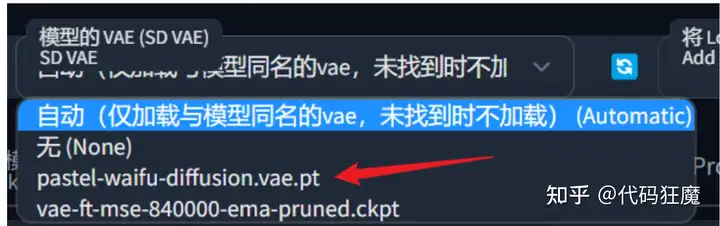
重启下WebUI,在顶部即可看到VAE的设置,选择pastel-waifu-diffusion.vae.pt,也可以下载其他的VAE,其他模型画面灰或者面部崩毁也可以尝试一下,VAE简单理解就是模型的一个补丁,用于优化。
第1、2、4、8张看起来还是不错的

写实风Realistic
写实风格
一些Lora可能不匹配,出现了上古神图

梦幻风Dreamlike
梦幻风格
emm确实比较梦幻

模型对比
上面都在说同一个模型在不同Lora下的表现对比,下面可以对比一下不同的模型在同一个tag下的表现,下图包含上面所有模型,按照列出模型的顺序依次对比,可以对模型的差别有更好的认识

奇淫技巧
主要是操作上面的一些技巧,并不能提高造图质量
- 在生成按钮上右键可以一直跑图,跑到显卡炸为止
- 点击这个粉色按钮可以显示模型、Lora等

鼠标放到封面上面还可以将当前生成的图片制作成封面替换,便于以后查找,如
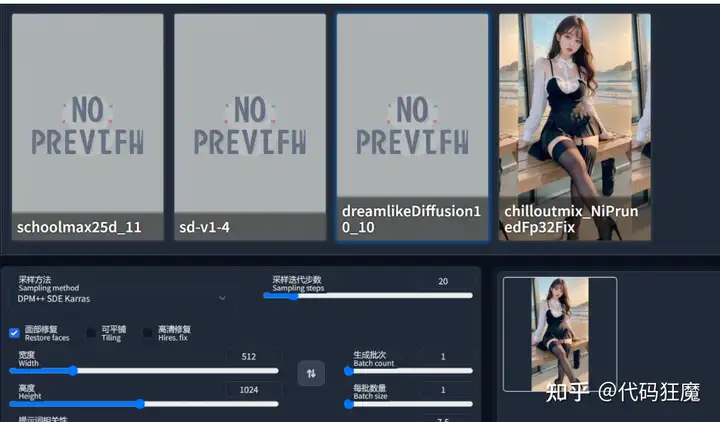
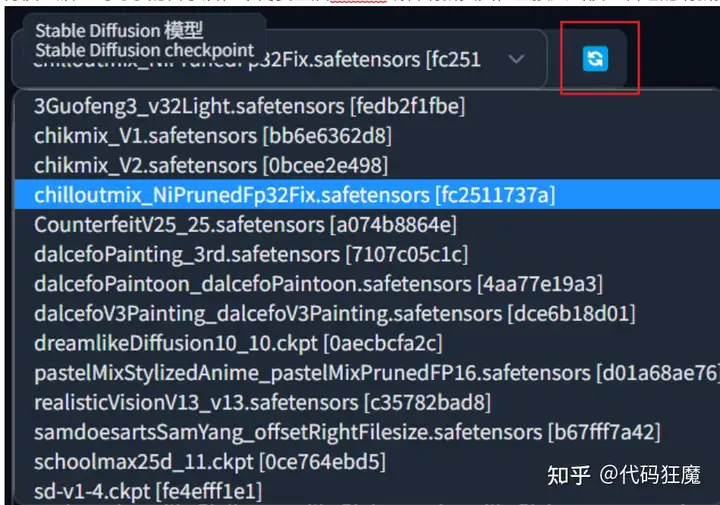
将模型放入到对于的目录后,不需要重启WebUI或者刷新页面,直接点击模型右边的刷新按钮即可加载
![图片[59]-5分钟系列:5分钟学会2023年最火的AI绘画(文生图)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[60]-5分钟系列:5分钟学会2023年最火的AI绘画(文生图)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏








暂无评论内容