
目录如下

2023-04-08_5分钟学会2023年最火的AI绘画(Lora模型训练入门)
系列文章目录请看第一篇:
2023-03-10_5分钟学会2023世界顶级AI绘画神器Stable Diffusion(入门篇)
交流可加扣裙:四二642八九七2
介绍
模型的训练一共分为四种
- Embeddings
- Hypernetworks
- Dreambooth
- LoRA
其中Embeddings和Hypernetworks是比较早期的做法,标准的Dreambooth和最常见的LoRA,早期的做法先且不论,下面说一下Dreambooth和LoRA的区别
- Dreambooth:Dreambooth直接拿样本数据
- 对整个模型进行微调,训练的成果可以直接保存在模型中,而且在模型风格和添加的图片之间可以得到不错的平衡,但是它生成的文件很大,很次都是一个ckpt文件,上G级别,如4G,相信有过使用经验都知道,模型太大每次会加载很久,另外Dreambooth训练对硬件要求很高,一般家用显卡显存为8G,Dreambooth训练最低要求12G,标准要求为24G
- LoRA:全名为Low-Rank Adaptation of Large Language Models(大语言模型的低阶适配器),简单来说就是大语言模型的微调小模型,在Checkpoint的大模型的下通过这个小模型可以进行微调,LoRA模型很小,最大的100+MB,最小的2~4MB,易于使用,训练快,对显存要求低,最低要求可以在6G显存显存上训练,从学习率来看,比标准的Dreambooth提高了100倍,另外一个好处是可以针对一个模型载入多个LoRA,但是LoRA有一个缺点是对模型的调整有限,而Dreambooth对模型的调整更加全面,总是大多数场景下还是利大于弊的,因此我们一般情况下会选择使用LoRA训练
LoRA建议学习率:1e-4=0.0001
Dreambooth建议学习率:1e-6=0.000001
LoRA的训练流程一般为:(好的LoRA训练集至关重要)
训练主题选择 > 训练集收集 > 训练集整理与清洗 > 训练集放大清晰化(可选) > 训练级分辨率预处理与打标 > 进行训练 > 对比查看训练结果
LoRA三种训练方式
目前有三种训练方式
- Kohya_ss,是目前比较主流产生LoRA的做法:https://github.com/bmaltais/kohya_ss
- Dreambooth扩展:Stable Diffusion WebUI上Dreambooth扩展也可以训练LoRA
后文将使用三种方式分别尝试LoRA的训练,这些训练工具的安装过程可能需要使用到科学上网,如果有类似于Connection reset、Connection refuse、timeout之类的报错多半是网络原因,请自备T子,此处不在赘述。
后续将在三种工具中修改必要参数,其他参数保持默认的情况下按照同样的训练集、同样的底模进行训练,然后在做横向和纵向的对比。
训练集准备(主题选择&清理&打标)
介绍
首先确认训练主题,一般入门就训练AI认识脸,当然主题还有许多,比如某种姿势动作、某种画风、某种服饰等等,这里就以入门的训练脸为主题。
巧妇难为无米之炊,首先当然准备好训练集,训练集很重要,这直接影响到最后训练的效果,因此需要进行挑选,训练集看质不看量,一般准备15张以上照片,找一个你喜欢的明星或者动漫人物,大多数教程并没有说明如何寻找训练集,可以从以下网站寻找训练集,照片质量还是不错,毕竟经过人工(用户)筛选
- 堆糖:https://www.duitang.com
- 花瓣:https://huaban.com
- pinterest:https://www.pinterest.com
优质训练集定义如下
- 至少15张图片,每张图片的训练步数不少于100
- 照片人像要求多角度,特别是脸部特写(尽量高分辨率),多角度,多表情,不同灯光效果,不同姿势等
- 图片构图尽量简单,避免复杂的其他因素干扰
- 可以单张脸部特写+单张服装按比例组成的一组照片
- 减少重复或高度相似的图片,避免造成过拟合
- 建议多个角度、表情,以脸为主,全身的图几张就好,这样训练效果最好
训练集照片准备好后需要经过如下处理
- 对训练集继续修复,修复一些低像素照片和去除不必要的杂质,修复有两种方式
- 推荐:一是可以在Stable Diffusion的Extra页面进行批量简单高清放大
- 二是可以在Stable Diffusion的图生图+Tiled VAE插件进行批量修复(高级用法)
- 裁剪你的照片成512×512(显存比较高768×768也可以)的比例,批量裁剪有几种方法
- birme站点批量裁剪后批量下载,优势是可以自定义选取
- 利用picpick软件自己裁剪后用python脚本批量改名和批量二次裁剪,上手难度略高
- 推荐:使用Stable Diffusion自带的训练预处理工具进行裁剪,优点是简单方便,缺点是不能自定义选取
- 准备图片解析词,新建一个和图片名称一样的txt文件,里面输入对应照片的描述,可以使用自然语言,也可以使用关键词堆砌,注意是英文的(如
a
woman with a red lip and a blue background with a white background and a
red lip and a blue background with a white background, 1girl, close-up
, halftone, halftone_background, mole
, polka_dot, polka_dot_background, solo),也有下面几种方式
- 手动打标,不推荐,相当于给AI打工,不利于打工人的身心健康
- 推荐:推荐用Stable Diffusion 自带的训练预处理工具进行识别打标
- 打标优化,编辑我们生成好的解析词文件,加入我们的关键人物tag,如果是服饰图片,可以给服饰加上我们自定义的tag用于区分服饰,相同的发型也可以打上发型的自定义tag,后面使用该LoRA模型可以加上服饰或发型部分的tag用于生成对应要求的图像,人物我们可以增量加入常用的tag如
face,nose,lips,hairstyle,eyes,ears,forehead,breast
- 等,批量添加关键词有几种方式
- 批量添加相同关键词可以直接在git bash,下面的命令可以给每个txt文件末尾增加字符串
,white shirt,,添加其他的内容照这个改就行了
ls | grep txt | xargs -i echo “echo -n ‘,white shirt
- ,’ >> {}” | bash
- 推荐:也可以使用BooruDatasetTagManager进行批量打标,其内置了一个文本的tag库,可以针对每张照片针对性打标,如下所示
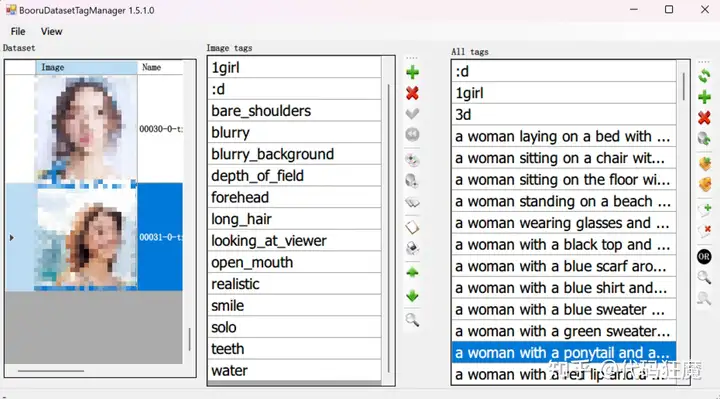
此处我们以绅士们都喜欢的一哭二闹三上不优雅为例,通过各种渠道找到对应的训练集后(为了避免不必要的麻烦训练集就不展示了,按照我们上文定义的优质训练集去寻找即可)
高清修复
在打标之前先对图像进行修复,在Stable Diffusion的Extra页面进行修复,可以先在Single中进行单张参数调整,如下所示
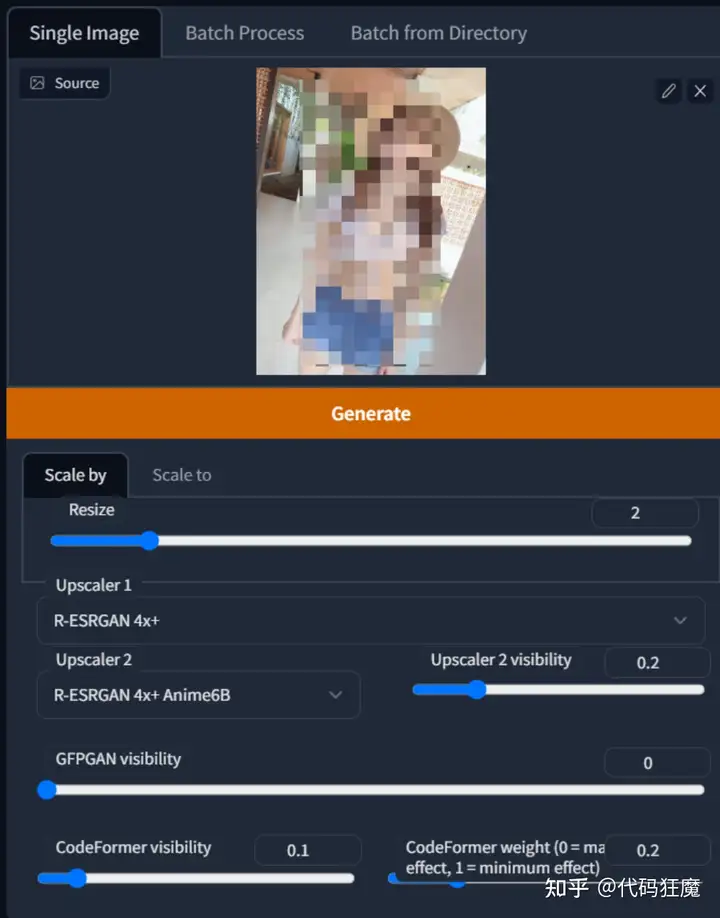
单张参数调整不错之后可以使用批量处理
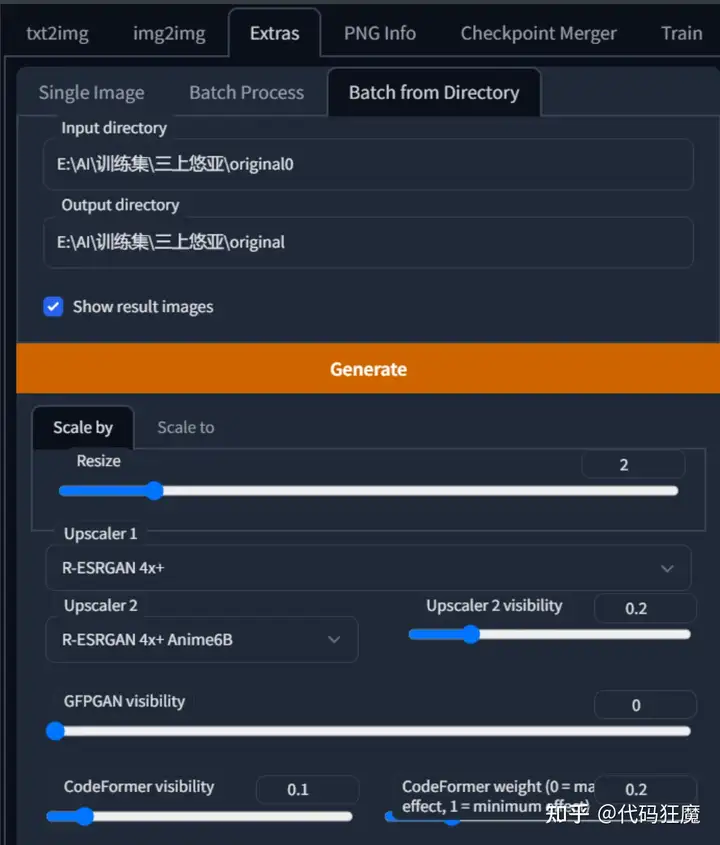
这边找一张其他照片对比下高清修复的效果,使用Extra放大后效果如下,可以看到放大之没有了像素点,这种方式是尊重原图的,因为它没有重绘,但是细节只是涂抹了,几乎没有增加细节,但肯定比没处理要好

另外注意在处理后会产生一张原图和一张压缩的图片,需要手动删除一下原图,原图一般比较大,在进行打标预处理时可能会报错,或者在设置里面找到最大限制,如下为4MB,那么超过4MB的都是需要删除的。

高级高清修复(可选)
注意这是可选的,它的优点是放大之后能增加细节(因为做了重绘),缺点是耗时特别长,并且参数不正确的情况下和原图差别比较大,不尊重原图,也就起不到训练的效果
这种方法在之前的文章中其实有介绍,可以回顾下之前的文章:2023-04-01_5分钟学会2023年最火的AI绘画(4K高清修复),在使用之前需要安装multidiffusion-upscaler-for-automatic1111插件
在Stable Diffusion选择图生图,如下所示,首先模型选择很重要,这直接关系到修复后的效果,建议按照后续将要训练的底模一致,就是在使用底模训练之前先使用底模增加一些图片细节。
正负向tag只保留和图片质量相关的,正向可参考:masterpiece
,best quality, realistic
, highres,photorealistic,8k wallpaper
负向可参考:low quality,normal quality, worst quality, bad anatomy
, extra breasts,extra nipples,extra hands,bad legs, bad feet,extra feet, bad fingers,confused fingers, extra fingers
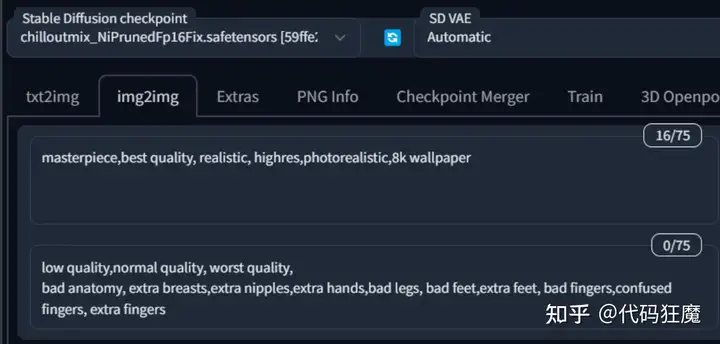
脸部修复和重绘幅度很重要,可能直接影响到修复结果
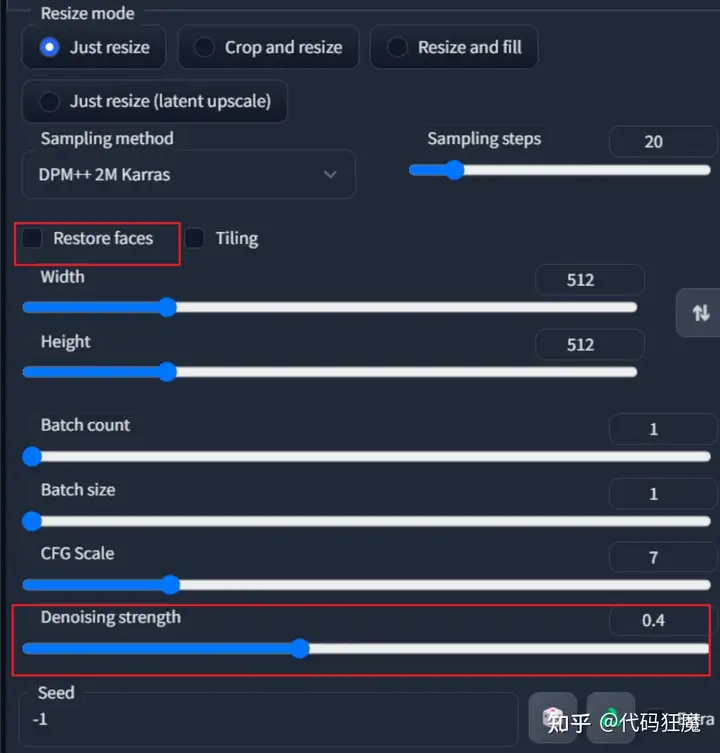
其余参数按照下面选择即可
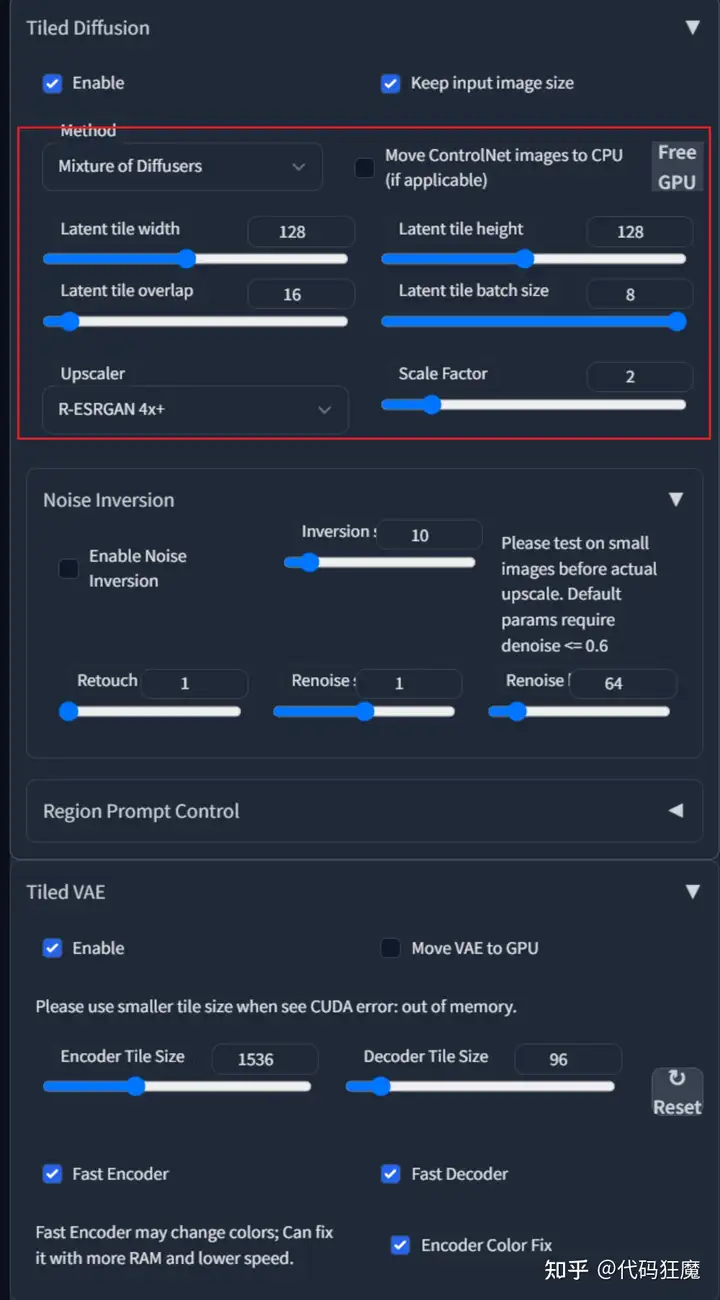
思路也是先修复一张看看效果,效果OK了再去批量处理中进行批处理,下图所示为批处理界面
下面对比一下不同参数的修复效果
- 重绘幅度0.3、无脸部修复,结果还是比较尊重原图的,重绘幅度不宜过小或者过大,过小不能增加细节,过大不像原图,要在修复和尊重原图之间找一个平衡点

- 重绘幅度0.3、有脸部修复,脸部修复效果不好这里就不展示了
- 换一个国风模型、重绘幅度0.3、无脸部修复,虽然不太尊重原图(有转手绘效果,这是模型选择的原因),但是细节还是不错,如果本来就是要国风模型作为底模那也可以这样修复。

打标
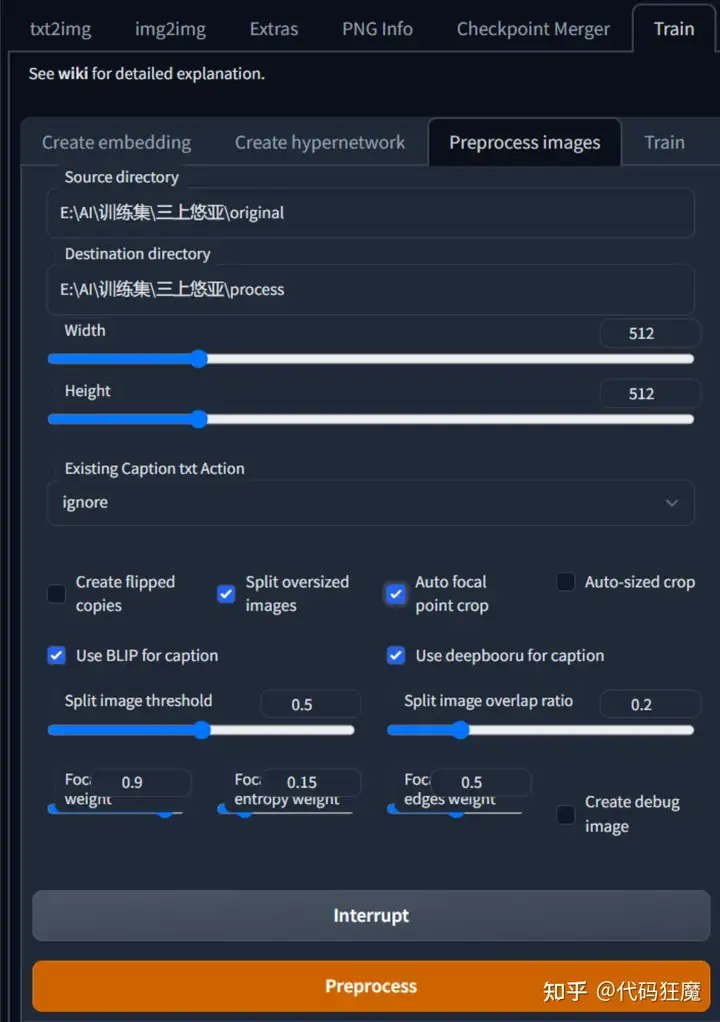
直接在Stable Diffusion的训练预处理中裁剪和打标,方便快捷,推荐使用,如下图所示
- Source directory:选择收集的训练集目录
- Destination directory:选择处理后的目录,目录不存在将会新创建
- Auto focal point crop:一般勾选上,在裁剪的时候将会以人物的脸部为中心进行裁剪
- Width & Height:宽和高设置为512即可
- Split oversized images:如果图像太大,将会分割成多张,而不是选择丢弃剩下的,可以勾选
- Create flipped copies:图片少于15张建议勾选,会创建一张左右镜像的训图片
- Use BLIP for caption:使用自然语言解释图片,建议勾选
- Use deepbooru for caption:使用关键词堆砌解释图片,建议勾选
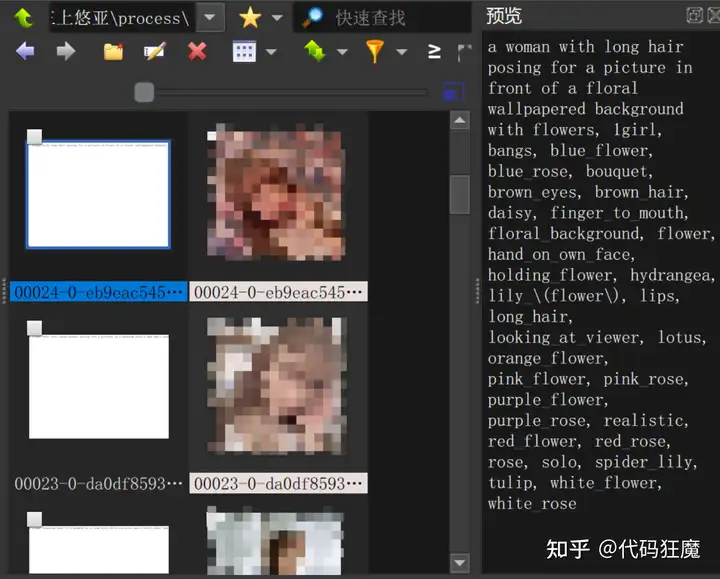
点击Preprocess进行预处理,预处理完成后如下所示,它将会自动重命名,会给每一图片加上一个同名的文本文件
存放tag,在对生成的tag进行核对,批量增加或者使用上文提到的BooruDatasetTagManager进行批量处理
到此为止训练集就准备好了,下面分别介绍一下三种训练方式
模型不符合预期的可能原因
- 图片分辨率低:可能导致人物面部的崩坏,有全身照但生成人物依然崩坏原因也可能是训练时人物照片分辨率低
- 裁剪问题 :如果裁剪的只有脸部图片,那么你只能得到脸图,或者扭曲的半身照,可以按照比例进行图片组合。
- 构图复杂:多个人或者构图复制,尽量让你的人物单独出镜,裁剪或者抹掉其他人或复杂的东西。
- 图片相似成都高:重复或高度相似,这会造成过拟合
- 底模:训练选择的基底模型问题
- 参数:训练时参数设置不合理
方式一:Kohya’s GUI
Kohya’s GUI基于Windows系统提供了可以用于Stable Diffusion模型训练的GUI界面,GUI 允许您设置训练参数并生成和运行所需的 CLI 命令来训练模型,它是一个All in One的程序包(傻瓜包)整合了训练用的所有软件,还有图形用户界面。所有软件都是在它自己的运行环境里运行,不会干扰其他的程序软件,安装kohya_ss非常简单,唯一要求是需要科学上网。
Kohya’s GUI 的好处就是让训练模型的工作交给独立软体去运作,不再跟Stable Diffusion web UI一同运行,毕竟Stable Diffusion web UI 常常更新容易造成相关扩展错误等问题,非常麻烦。
项目地址:https://github.com/bmaltais/kohya_ss
安装
打开gitbash,输入如下命令,其中目录的名称(dir变量)需要自行定义,不要使用中文和空格,此处以/e/AI/train为例
dir=/e/AI/train
mkdir -p $dir && cd $dir
git clone https://github.com/bmaltais/kohya_ss
cd kohya_ss
./setup.bat然后接下来会装一堆依赖,其中比较大的是pytorch包(2.4G)、tensorflow包(455MB)、xformers包(184MB),此处如果很慢可尝试科学后进行下载,否则够得等
Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu116
Collecting torch==1.12.1+cu116
Downloading https://download.pytorch.org/whl/cu116/torch-1.12.1%2Bcu116-cp310-cp310-win_amd64.whl (2388.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/2.4 GB 764.8 kB/s eta 0:51:41注意安装到一半会进行如下选择,参考如下,注意在Windows下安装DeepSpeed一定要选择NO,DeepSpeed是一个加速训练的库,选择NO是因为DeepSpeed模块不支持Winodws,比较搞笑的是这个库是微软开发的,所以这里不要踩坑了,详情见issue
[REQUEST] Hey, Microsoft…Could you PLEASE Support Your Own OS? #2427
如果选错了,重新执行setup.bat可重新选择
In which compute environment are you running?
Please select a choice using the arrow or number keys, and selecting with enter
* This machine
AWS (Amazon SageMaker)
Which type of machine are you using?
Please select a choice using the arrow or number keys, and selecting with enter
* No distributed training
multi-CPU
multi-GPU
TPU
MPS
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO
# Nightly版本的PyTorch才支持dynamo,这里选择NO
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
# 注意在Windows环境下要选NO
Do you want to use DeepSpeed? [yes/NO]:No
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
Do you wish to use FP16 or BF16 (mixed precision)? NOCUDNN 8.6,如果是30系或者40系显卡可开启该特性,它可以提供更高的批处理大小和更快的训练速度,在4090上几乎可以提速50%,需要可以在如下链接下载,大概600+MB,这也是作者提供的链接
下载完成后解压到项目根目录,执行如下命令安装
# 激活venv
./venv/Scripts/activate.bat
# 安装
python ./Tools/cudann_1.8_install.py
# 回显如下
[ ] xformers version 0.0.14.dev0 installed.
[!] bitsandbytes NOT installed.
[!] diffusers NOT installed.
[!] transformers NOT installed.
[!] torch version 2.0.0+cu118 installed.
[!] torchvision version 0.15.1+cu118 installed.
Checking for CUDNN files in C:UsersxxAppDataLocalProgramsPythonPython310Libsite-packagestorchlib
Copied CUDNN 8.6 files to destination启动
启动就很简单了,直接使用如下命令即可,和Stable Diffusion类似
./gui-user.bat能看到如下界面说明安装成功
训练
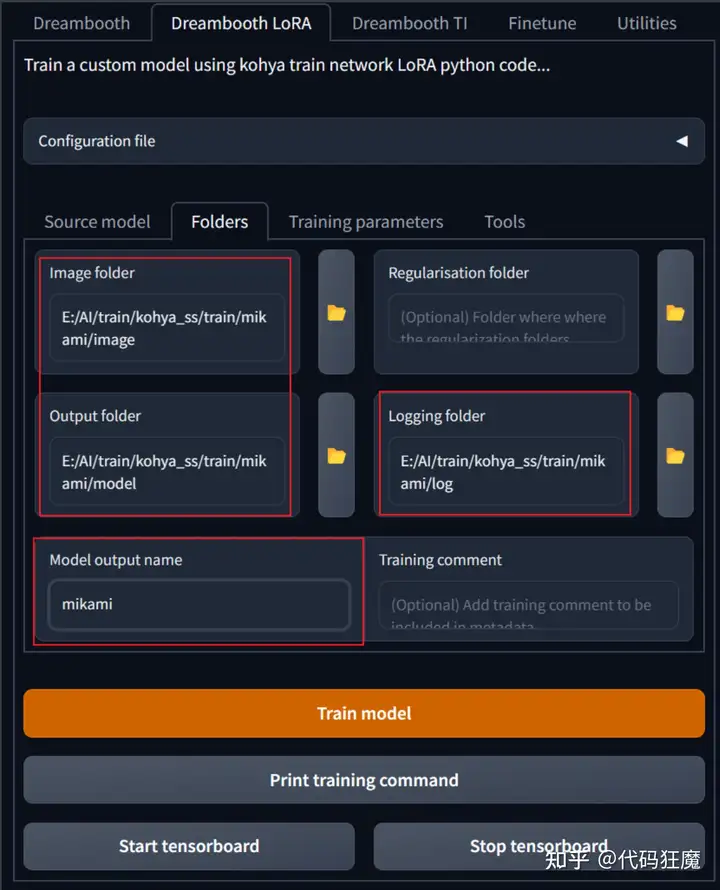
首选准备三个目录
- image
- log
- model
在image目录中新建一个目录100表示每张照片训练100步,然后将上面准备好的训练集放到该目录中,即image/100,假设准备了20张照片,此处需要训练100 * 20 = 2000步
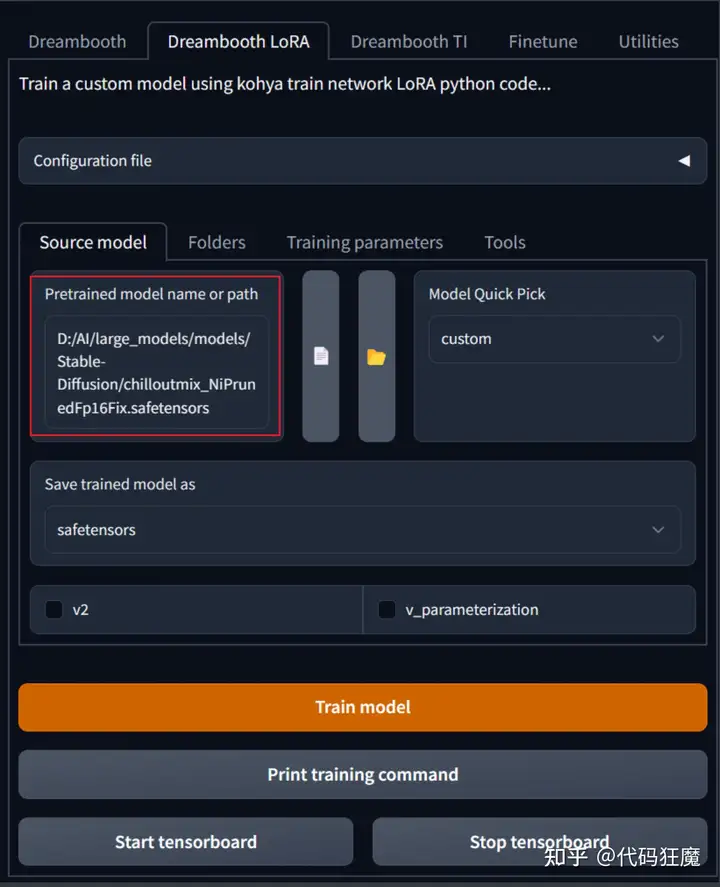
目录准备好后找到打开Dreambooth LoRA选项,选择底模,因为我们是真人训练,所以底模选择喜闻乐见的chilloutmix_NiPrunedFp16Fix.safetensors
几个目录对应选择好,注意要选择目录100的上一层目录,即image,最终模型的名字设定好,此处就以三上不优雅的假名mikami命名。
batch size,笔者显存12G可设置为4,根据实际情况先择,如果显存比较小建议保持为1就行,batch size为4表示一次处理4张图片,因此需要的步数为2000/4=500步,batch size越大训练时间越短
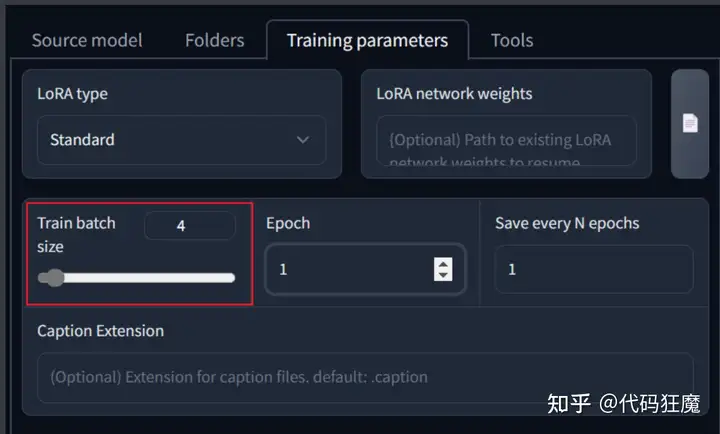
最后点击页面末尾的Train model即可,此时页面上并没有任何反应,要观察控制台,如下输出表示正在训练中
...
use 8-bit AdamW optimizer | {}
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 2700
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 675
num epochs / epoch数: 1
batch size per device / バッチサイズ: 4
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 675
steps: 3%|█████▍ 20/675 [00:25<13:51, 1.27s/it, loss=0.106]根据输出可以得知
- 需要训练675步,因为batch size设置为4,所以一共的步数应该为675 * 4 = 2700步
- 一共需要13:51分钟训练完
- 当前的速度为1.27s/it,即1.24s一步
- 当前的loss值为0.106,越小表示学习得越好
以上参数只是最简单的参数设置,可以看到UI上面的参数非常复杂,感兴趣可以自行插尝试,训练完成后可以看到输出目录产生了我们的模型文件,这个文件大概9.3MB左右
- mikami.safetensors
为了便于后续区分,我们更改为如下名称
- mikami-kohyaGUI.safetensors
方式二:秋叶的脚本(Akegarasu/lora-scripts)
安装
通过仓库可以参考秋叶的脚本也是基于kohya-ss的脚本,Kohya’s GUI只是在这基础之上套了一个UI
教程可参考秋叶官的视频教程:https://www.bilibili.com/video/BV1fs4y1x7p2
秋叶的脚本比较方便的是已配置了国内mirror,不用担心网络问题,下载完成后
dir=/e/AI/train
mkdir -p $dir && cd $dir
git clone https://github.com/Akegarasu/lora-scripts
# 由于秋叶的脚本使用的是kohya的sd-scripts,因此还要再次下载该脚本
cd lora-scripts && rm -rf sd-scripts
git clone https://github.com/kohya-ss/sd-scripts.git下载完成后使用PowerShell命令行的方式执行install-cn.ps1即可,由于PowerShell默认是禁止脚本执行的,执行下面命令手动打开一下就好
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned训练
下面进行目录准备,这里引用一张秋叶视频教程的图,每个主题可以用一个目录区分,比如face、body等,此处由于我们训练集比较少,就不区分了,前面的数字代表每张照片的训练步数,5表示每张照片训练5次
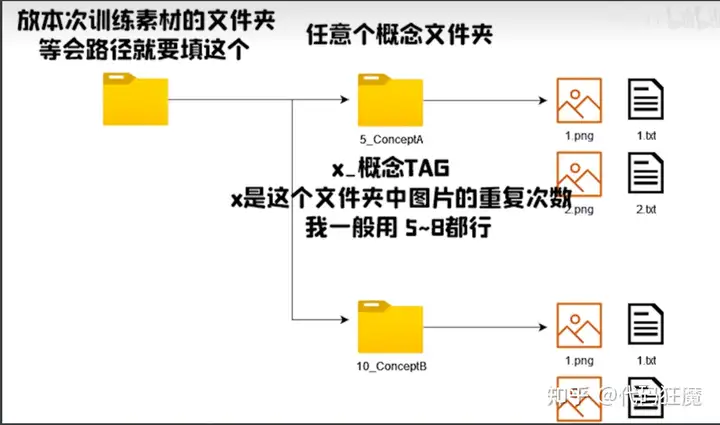
我们创建一个目录10_mikami,将训练集剪贴到里面,这个目录可以随便放哪里都可以,表示每张照片训练10次
然后打开train1.ps1脚本编辑,此处建议拷贝一个文件打开,不要修改原始文件,打开后修改如下几个参数,其他的保持默认就好
# base model path | 底模路径
$pretrained_model = "D:AIlarge_modelsmodelsStable-Diffusionchilloutmix_NiPrunedFp16Fix.safetensors"
# train dataset path | 训练数据集路径,即我们上面准备的10_mikami,注意要选他的上一层路径
$train_data_dir = "./train/mikami"
# image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
$resolution = "512,512"
$batch_size = 4 # batch size
# max train epoches | 最大训练 epoch
$max_train_epoches = 12
# save every n epochs | 每 N 个 epoch 保存一次
$save_every_n_epochs = 4
# output model name | 模型保存名称,我们存储为mikami-qiuye用于区分
$output_name = "mikami-qiuye"
# model save ext | 模型保存格式 ckpt, pt, safetensors
$save_model_as = "safetensors" 其中最大训练epoch(max_train_epoches)即循环次数为12次,每4次保存一次,batch_size设置的为4,因此步数计算公式为
图片张数 x 每张训练步数 x 最大epoch / batch_size
按照我们的设置,有27张照片,每张训练10次,所以每个epoch为270步,一共12个epoch,因此270 * 12为3240步,由于我们的batch_size为4,因此3240 / 4 = 810步
设置好上面的脚本后右键该脚本,选择使用Power Shell执行,此处黑屏比较久,需要耐心等待一下,稍等一会儿可以看到控制台的输出,输出和Kohya’s GUI大同小异,此处不在赘述。
use 8-bit AdamW optimizer | {}
override steps. steps for 12 epochs is / 指定エポックまでのステップ数: 816
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 270
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 68
num epochs / epoch数: 12
batch size per device / バッチサイズ: 4
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 816可以看到最终是816步,比算出来的多6步,可能和算法有些关系,训练完成后可以脚本目录下找到output目录,里面即是保存好的LoRA,由于我们一共12个epoch,每4个epoch保存以此,因此是三个文件,其中mikami-qiuye.safetensors是跑完12个epoch的文件
- mikami-qiuye-000004.safetensors
- mikami-qiuye-000008.safetensors
- mikami-qiuye.safetensors
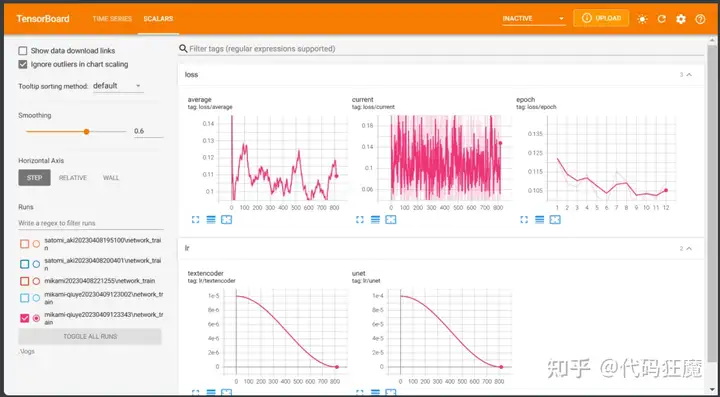
另外相较于Kohya’s GUI的不同是,秋叶的脚本带有一个训练结果的图标,可以看训练过程中的各种数据,找到脚本根目录下的tensorboard.ps1,右键Powser Shell运行,起来之后访问控制台打印的URL:http://localhost:6006,如下所示
方式三:Dreambooth扩展
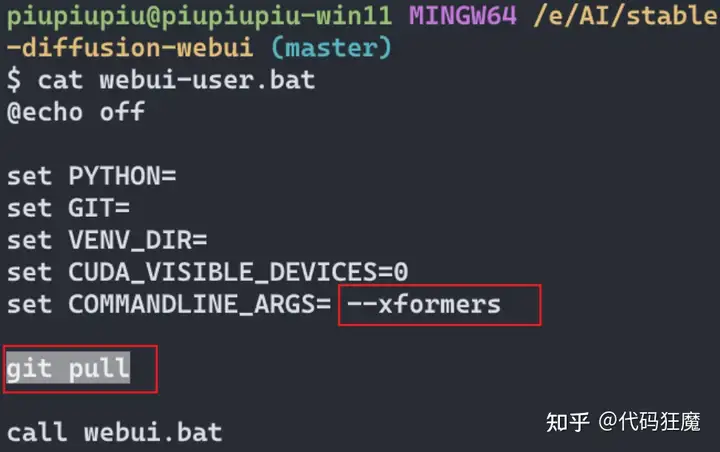
首先打开Stable Diffusion WebUI,安装如下扩展,注意在安装之前最好更新一下WebUI,使用git pull更新即可,否则可能导致版本不兼容问题
安装完成一定要重启WEBUI,重启之后会安装Dreambooth,会在控制台打印xformers版本,如果版本不在0.0.17.dev则会有问题,在控制台有打印类似信息,它告诉了我们怎样升级的步骤
# Your version of xformers is 0.0.16rc425.
# xformers >= 0.0.17.dev is required to be available on the Dreambooth tab.
# Torch 1 wheels of xformers >= 0.0.17.dev are no longer available on PyPI,
# but you can manually download them by going to:
https://github.com/facebookresearch/xformers/actions
# Click on the most recent action tagged with a release (middle column).
# Select a download based on your environment.
# Unzip your download
# Activate your venv and install the wheel: (from A1111 project root)
cd venv/Scripts
activate
pip install {REPLACE WITH PATH TO YOUR UNZIPPED .whl file}
# Then restart your project.
[!] xformers version 0.0.16rc425 installed. # xformers 版本不符合要求
[+] torch version 1.13.1+cu117 installed.
[+] torchvision version 0.14.1+cu117 installed.
[+] accelerate version 0.18.0 installed.
[+] diffusers version 0.14.0 installed.
[+] transformers version 4.26.1 installed.
[+] bitsandbytes version 0.35.4 installed.可尝试使用如下命令更新xformers
venvScriptsactivate
python.exe -m pip install --upgrade xformers==0.0.17rc482
# 可选,上面的不行执行下面的命令
venvScriptsactivate
pip install --force-reinstall torch torchvision --index-url https://download.pytorch.org/whl/cu118
pip install xformers==0.0.18
# 如果PIP有问题,更新下pip
venvScriptsactivate
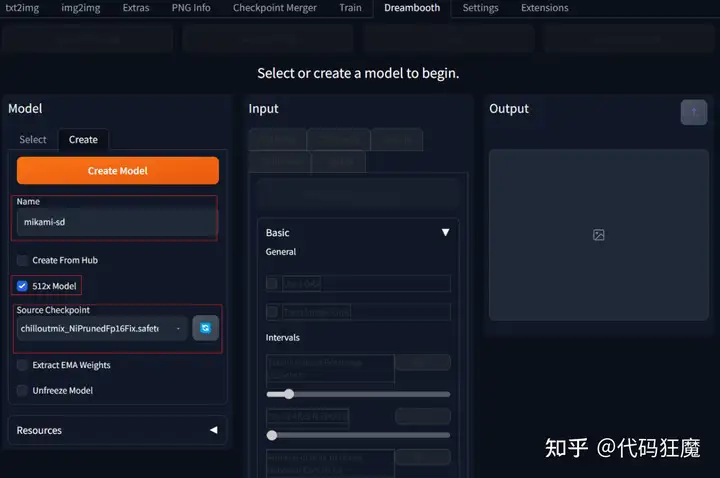
py -m pip install --upgrade pip安装好之后界面如下,输入名字,这里取名为mikami-sd表示是在sd的Webui中生成的,用作后续对比,选择512xModel,表示是sd 1.x版本的模型,分辨率默认是521×512,Source Checkpoint表示底模选择,和之前保持一致即可,输入完成后点击Create Model创建模型,大概需要2分钟创建完成
创建完成后点击Use LORA表示使用LORA训练
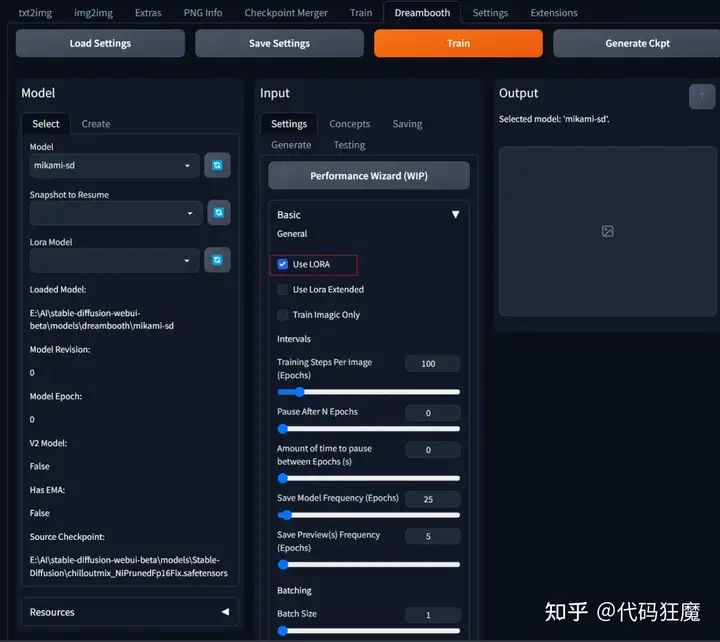
Settings页中参数如下填写,训练的Epochs,一般填写100~500,这里我填写200,表示每张照片训练200次
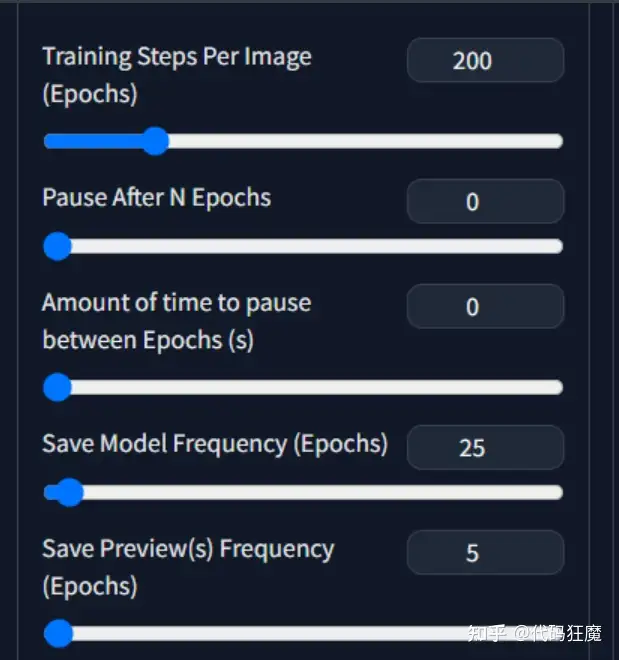
这两个选项很重要,不勾选可能导致训练报错:RuntimeError: CUDA error: invalid argument,isseu可以参考:
This issue should be related to using xformers without fp16 and 8bit adam. Set precision to “fp16” and check “Use 8bit adam” in advanced settings before training, or run without the –xformers flag.
还可以参考其他类似issue

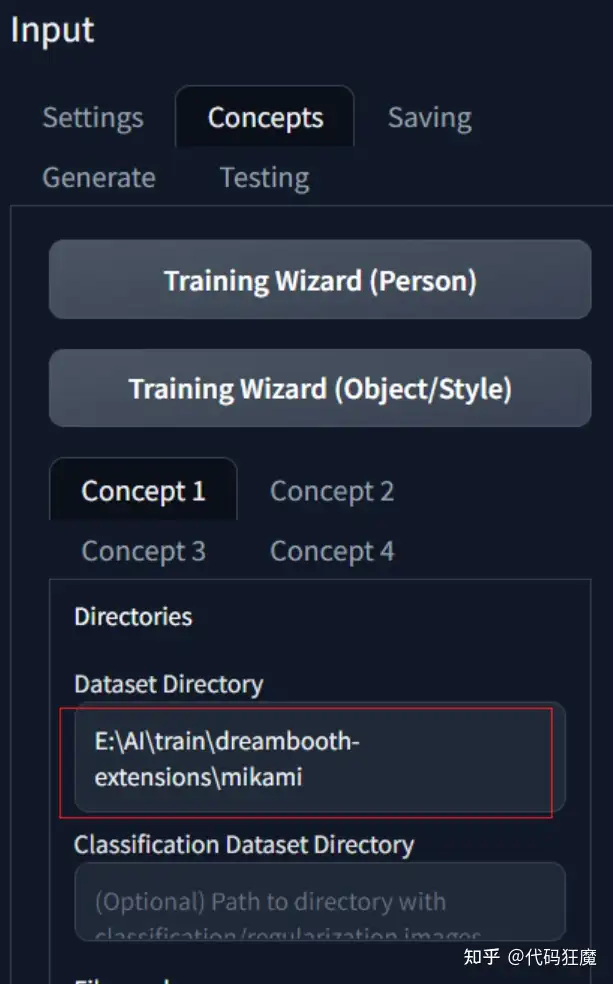
其他保持默认就好,下面填写Concept,表示概念,和秋叶脚本中提到的概念是一个含义,这里最多可以同时4个概念,填入对应训练集目录即可,注意这里直接填写的是训练集的目录,不用填写到上一层,和之前的方式有所不同,需要注意.
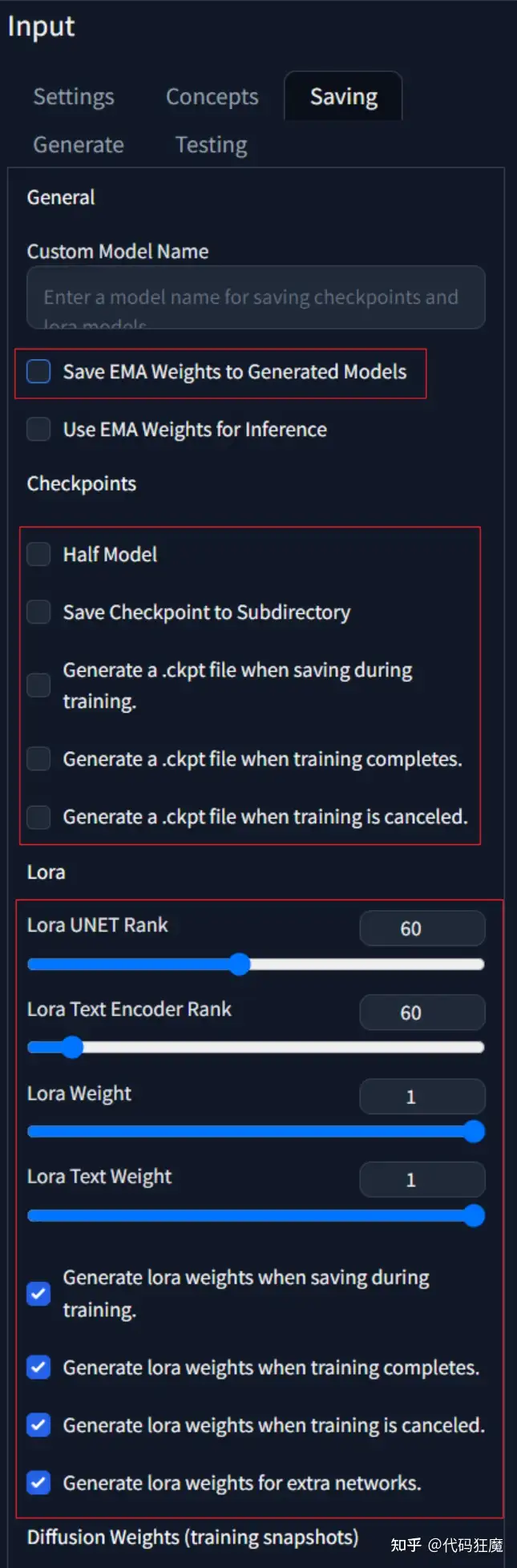
在Saving页面需要按照如下进行填写,取消掉EMA和checkpoint相关的选项,勾选上和LoRA相关的选项。Lora UNET Rank和Lora Text Encoder Rank可以适当提高,。
然后就可以点击顶部的保存,保存后点击Train开始训练
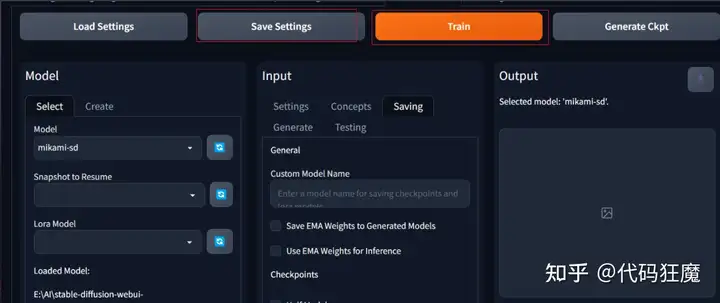
在控制台看到如下界面表示训练成功开始
...
Initializing bucket counter!
***** Running training *****
Num batches each epoch = 27
Num Epochs = 100
Batch Size Per Device = 1
Gradient Accumulation steps = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Text Encoder Epochs: 0
Total optimization steps = 2700
Total training steps = 2700
Resuming from checkpoint: False
First resume epoch: 0
First resume step: 0
Lora: True, Optimizer: 8bit AdamW, Prec: fp16
Gradient Checkpointing: True
EMA: False
UNET: True
Freeze CLIP Normalization Layers: False
LR: 0.0001
V2: False
Steps: 5%|█ | 135/2700[01:11<21:22, 2.00it/s, inst_loss=0.0689, loss=0.0689, lr=0.0001, prior_loss=0, vram=4.7]最后在WebUI的LoRA目录,即stable-diffusion-webui/models/Lora中找到训练的模型文件,其中文件后面的数字代表训练步数
- mikami-sd_675.safetensors
- mikami-sd_1350.safetensors
- mikami-sd_2025.safetensors
- mikami-sd_2700.safetensors
测试LoRA
LoRA训练完成后,需要进行测试,测试思路是先找到每个工具产生的LoRA最好的那个,做一个纵向对比,然后最好的在进行横向对比。
安装与配置
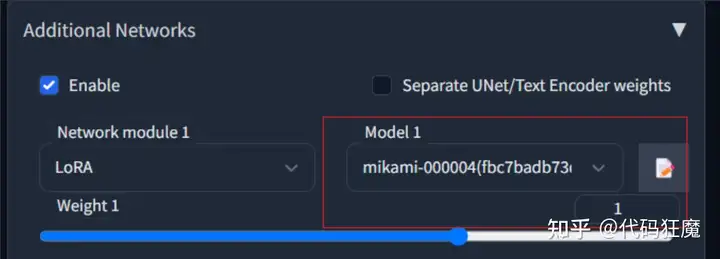
首先打开Stable Diffusion WebUI,安装扩展xx,该扩展可支持在X/Y/Z图标中定义不同的LoRA,方便对最终效果进行对比
安装好后将上面产生的所有LoRA全部复制到插件的lora目录下:extensions/sd-webui-additional-networks/models/lora,目前为止我们一共产生了如下LoRA
# kohyaGUI
9.2M 4月 9 12:15 mikami-kohyaGUI.safetensors
# 秋叶的脚本
37M 4月 9 12:51 mikami-qiuye.safetensors
37M 4月 9 12:40 mikami-qiuye-000004.safetensors
37M 4月 9 12:45 mikami-qiuye-000008.safetensors
# dreambooth扩展
72M 4月 9 16:46 mikami-sd_1350.safetensors
72M 4月 9 16:51 mikami-sd_2025.safetensors
72M 4月 9 16:57 mikami-sd_2700.safetensors
72M 4月 9 16:41 mikami-sd_675.safetensors复制进去后打开文生图界面,点击左上角开启,模型随便选择一个,这里的模型就是刚才复制的LoRA,权重随便写一个1
重点在X/Y/Z图表中按照如下设置,X选择模型,点击右侧的黄色图标可以加载所有的模型,Y填写权重,分别使用0.5,0.8,1.2,1.4,2的权重
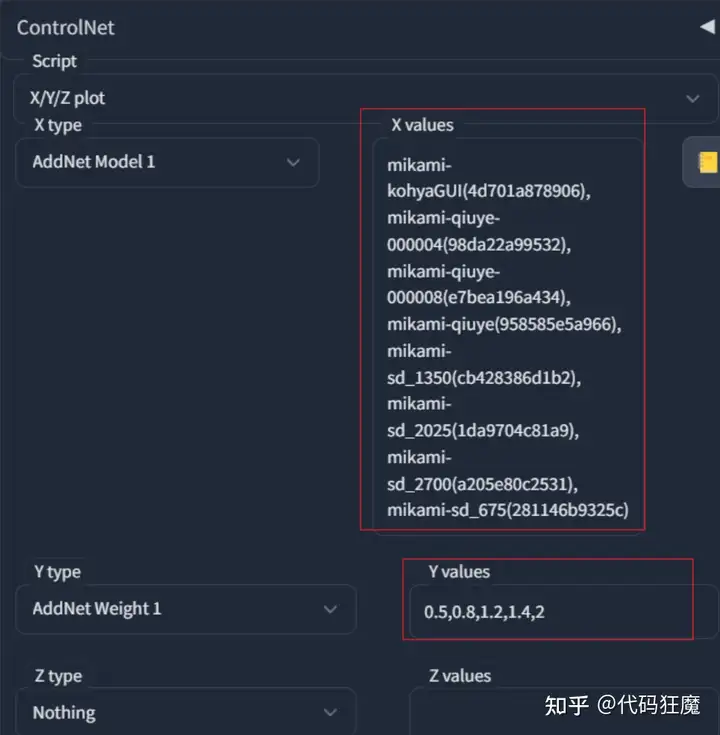
第一轮测试
关键词可以找一张训练集中的txt文本,在加上一些通用的质量描述,本次使用如下tag
正向:
(8k, RAW photo, best quality, masterpiece:1.4), realistic, photo-realistic, ultra-detailed,
a woman with a hat on her head posing for a picture in a room with a pink wall and a wooden floor,
1girl, bangs, brown eyes, red hair, lips,shopping mall rooftop cafe, outdoor, smile, (high detailed skin:1.4), puffy eyes, gorgeous hair, air bangs, brown black hair, white opaque shirt with bow tie, pure red pleated skirt, soft lighting, high quality
反向:
EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,(watermark:1.2),(white letters:1/1)模型选择底模
然后开始生成图片,此时会按照脚本定义的LoRA和权重分别生成图片,最终是一个如下的超大的LoRA和权重的矩阵图

其中比较像的用红框框出来了,先从LoRA维度看(从左往右,从上往下)
- 可以发现mikami-kohyaGUI还没练到位,权重0.5~1.4都不像,在权重2.0的时候比较像,而其他LoRA在权重2.0的时候全都崩了
- mikami-qiuye-000004在权重0.8和1.4的时候比较像,说明训练4个循环已经有效果了
- mikami-qiuye-000008在权重1.2和1.4的时候比较像,但是除了权重0.5以外,其他都是一个姿势,泛化性有点弱
- mikami-qiuye在0.8~1.4都比较像,但是和000008有一样的问题,过于向训练集靠拢了,有些过拟合
- mikami-sd系列在权重1.2~1.4都挺像
其次从权重维度看(从上往下,从左往右)
- 权重0.5基本不像
- 权重0.8~1.4除了mikami-kohyaGUI基本不像之外,其他都还行
- 权重2只有mikami-kohyaGUI挺像,其他全崩了
mikami-kohyaGUI(kohya`s GUI产生的LoRA)
既然mikami-kohyaGUI权重2表现最好,那将权重设置为2在随机生成看看效果,大部分时候表现不够好,不是脸崩就是姿势怪异

mikami-qiuye(秋叶脚本产生的LoRA)
使用的一样的tag,最右边那一列是None,不使用LoRA,用以对比,可以看到mikami-qiuye在权重1.0的时候表现比较好

应该看出可一个规律,训练步数越多,AI学习的过于饱和,权重给一点就会有效果,权重过会使得LoRA表现的像训练集本身,缺失泛化性,步数越少,AI学习不那么充分,可能导致权重给大很大依然不像。找两张高清修复试试,看久了就有种又像又不像的感觉

TAG在换一换,试试权重1.0,1.2,1.3

mikami-sd(SD中的Dreambooth扩展产生的LoRA)
乍一看似乎区别不大,训练了600+步骤的和训练了2700+步的差别不是很大,只是训练了2700步的在权重1.3,1.4的时候脸有些变形

抽卡几张看看

底模交叉
如果换一个底模什么效果呢,下面来试试,粉白嫩绿448×768,分别使用三个中最终生成的模型、权重1.2实验,像不像各位绅士自品吧,注意看表头,最右边那列为没有LoRA参与运算




最后将还不错的几张高清修复后送给各位绅士



参考
![图片[44]-5分钟系列:5分钟学会2023年最火的AI绘画(Lora模型训练入门)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[45]-5分钟系列:5分钟学会2023年最火的AI绘画(Lora模型训练入门)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏







暂无评论内容