
目录如下

之前章节中介绍的内容全部都是在AUTOMATIC1111的WEBUI中进行,这次来介绍一个不一样的UI,节点式的UI,通过拖拉链接节点继续不同功能的组合,形成自己独特专业的工作流,如下图所示,使用过节点式软件的朋友会比较熟悉
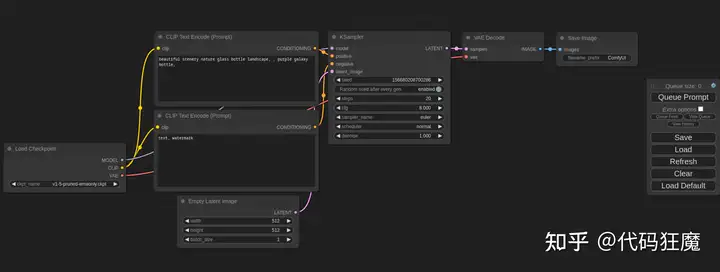
项目地址:https://github.com/comfyanonymous/ComfyUI
有如下特性
- 节点/图表/流程图
- 界面,无需编写任何代码即可试验和创建复杂的工作流程
- 支持SD1.x和SD2.x
- 异步队列系统
- 命令行选项:–lowvram 使其在 vram 小于 3GB 的 GPU 上工作(在 vram 低的 GPU 上自动启用)
- 没有显卡只有CPU也能用,加上对应命令行参数
- :
--cpu(很慢就是了) - 可以加载
ckpt,safetensors模型,标准的VAE和CLIP模型 - 支持Embeddings/Textual
- Loras(常规的、Locon 和 Loha)
- 从生成的 PNG图片文件加载完整的工作流程(带有种子)
- 将工作流保存/加载为 Json 文本文件
- 节点界面可用于创建复杂的工作流,例如用于 Hires 修复的工作流或更高级的工作流。
- 区域合并
- 使用常规模型和修复模型进行修复
- ControlNet 和 T2I 适配器支持
- 高清修复模型(ESRGAN、ESRGAN 变体、SwinIR、Swin2SR 等…)
- unCLIP 模型支持
- 启动非常快,这点很赞
- 完全离线工作:永远不会下载任何东西
- 用于设置模型搜索路径的配置文件,可从其他地方引入模型
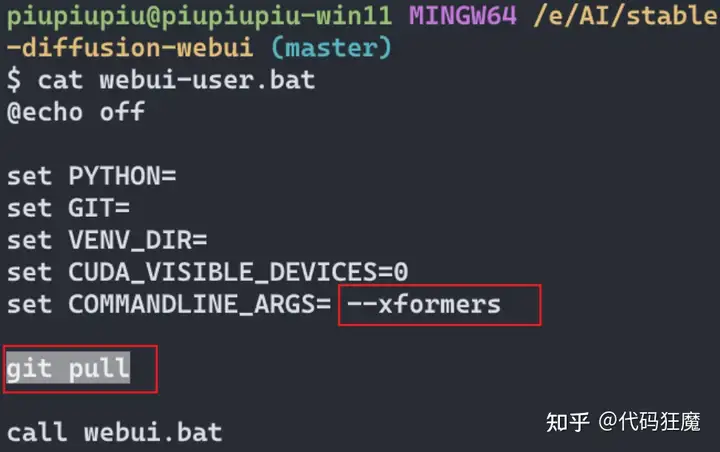
安装
安装很简单,作者很懂用户,已经提供好了一键安装包,去如下发布页面直接下载Windows的独立安装包解压即可
注意模型文件可以配置为别的路径,在配置文件ComfyUI/extra_model_paths.yaml配置即可,如下所示,根据实际情况配置即可,可以直接将AUTOMATIC1111的WEBUI下面的模型文件配置给ComfyUI,不用重新全部复制一遍
#Rename this to extra_model_paths.yaml and ComfyUI will load it
#config for a1111 ui
#all you have to do is change the base_path to where yours is installed
a111:
base_path: D:AIlarge_models
checkpoints: models/Stable-diffusion
configs: models/Stable-diffusion
vae: models/VAE
loras: models/Lora
upscale_models: |
models/ESRGAN
models/SwinIR
embeddings: embeddings
controlnet: extensions/sd-webui-controlnet/models
#other_ui:
# base_path: path/to/ui
# checkpoints: models/checkpoints双击里面的run_nvidia_gpu.bat文件即可运行,运行成功后打开http://127.0.0.1:8188即可访问
节点介绍
熟悉ComfyUI后可对Stable Diffusion的工作流程更加熟悉,也可以组合出更多用法,或许以前在A1111的WebUI中需要用插件才能实现的效果在ComfyUI通过节点的组合就能实现,打开之后是默认界面
- 首先可以看到有一个CheckpointLoaderSimple,这个节点就是在WebUI中选择模型的地方,点开可以看到一堆模型可以选择,其中CLIP分别指向了正向描述词和负向描述词,CLIP是什么意思呢?
CLIP(Contrastive Language-Image Pre-Training)是一种由OpenAI开发的神经网络模型
,它可以将自然语言和视觉信息进行联合训练,从而实现图像与文本之间的跨模态理解。
CLIP的训练方式是将大量的图像和文本样本组合在一起,然后让模型通过对这些样本的联合处理来学习表示图像和文本的特征。在训练过程中,CLIP通过最大化图像和文本之间的相似度来学习特征表示。具体来说,CLIP使用了对比学习(contrastive learning)的思想,通过将正样本对和负样本对进行比较,来学习如何将相似的图像和文本对应起来,而将不相似的图像和文本分开。
与其他图像-文本联合训练模型相比,CLIP的优势在于它可以处理各种类型的图像和文本数据,而不需要对它们进行显式的匹配。因此,CLIP可以用于各种视觉与语言任务,例如视觉问答、图像分类、图像生成、文本分类
- 等。
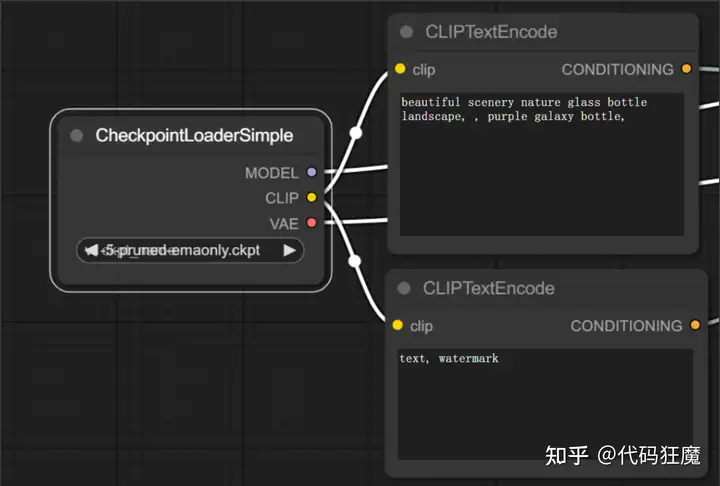
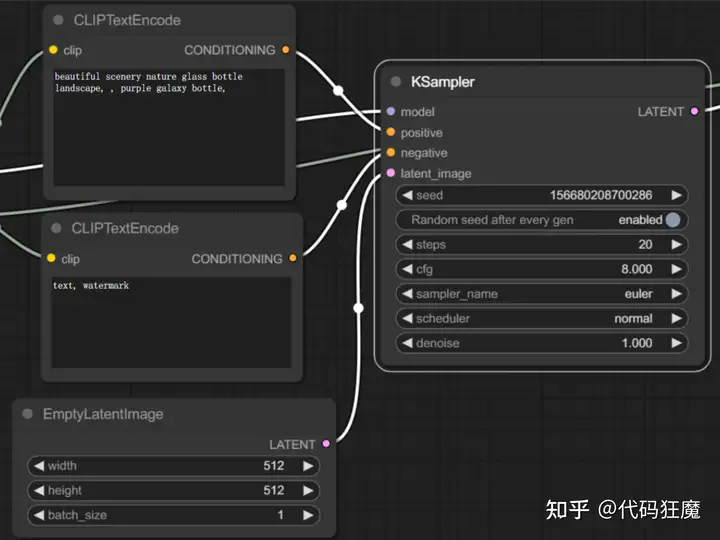
- CLIPTextEncode节点也就是正负向TAG分别链接到KSampler的Positive和Negative,model链接的即是上面提到的CheckpointLoaderSimple节点,latent_image上面链接了一个EmptyLatentImage模块,因为是一个文生图,所以会产生一个随机噪声图,EmptyLatentImage中可以设置图像的宽和高,KSampler即是WEBUI中的采样器
- ,可以调整采样方法、CFG等参数
- 最后可以看到有一个VAEDecode节点,前面的采样节点产生的其实是一个潜空间的图像,经过VAEDecode节点解码后还原到像素空间也就是我们最终生成的图像,在VAEDecode之前都是在潜空间中操作,注意VAEDecode中samples参数链接的是采样器节点,vae参数链接的是CheckpointLoaderSimple节点(也就是上面提到的模型选择器),最后别忘了还有一个SaveImage节点,用来展示和保存图形。
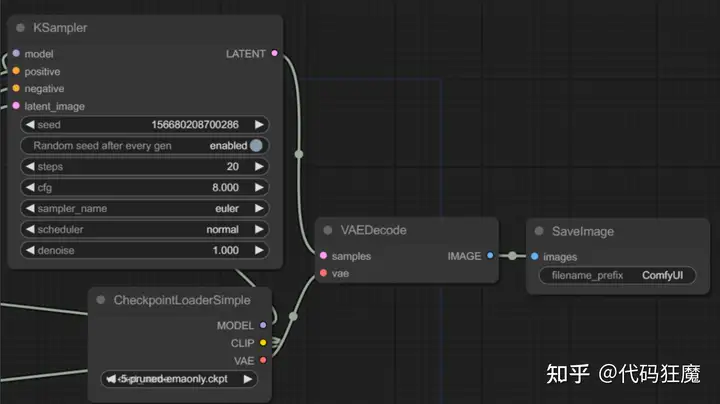
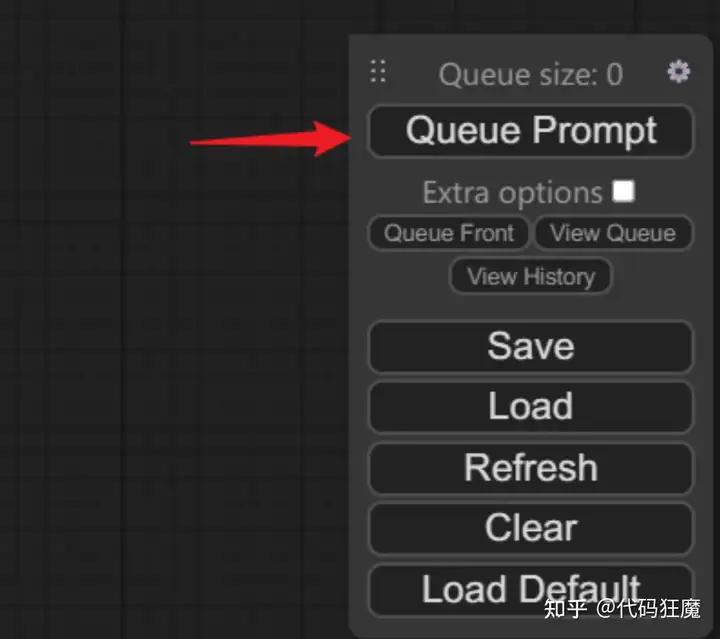
其实聪明的你已经看出来了:上面是一个文生图的流程,最后点击浮动工具栏
中的Queue Prompt即可进行文生图(多点几次可以排队),相当于点击了WebUI中的Generate生成按钮,注意默认要先在CheckpointLoaderSimple节点中选择模型,否则会报错。
工作流案列
作者给出了常用的工作流,对标WebUI中的功能,可以在这个项目找到
有趣的是作者还提供了一个教学小游戏,介绍里面的各个节点,感兴趣可以参考,里面的图片也是用ComfyUI生成的

常见的工作流如下所示:
“Hires Fix” aka 2 Pass Txt2Img
Img2Img
Inpainting
Lora
Embeddings/Textual Inversion
Upscale Models (ESRGAN, etc..)
Area Composition
Noisy Latent Composition
ControlNets and T2I-Adapter
GLIGEN
[unCLIP](https://github.com/comfyanonymous/ComfyUI_examples/blob/master/unclip
值得注意的是,可以直接加载图片即可加载对应的工作流,工作流的json信息都在图片的元数据中
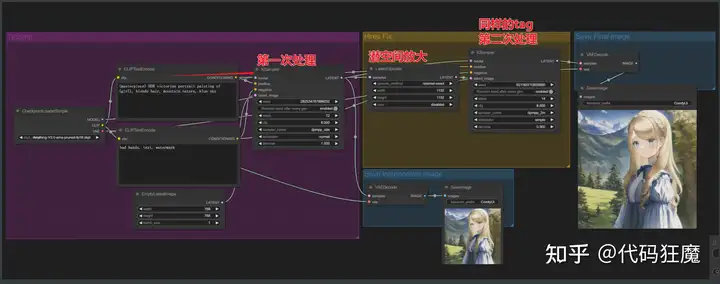
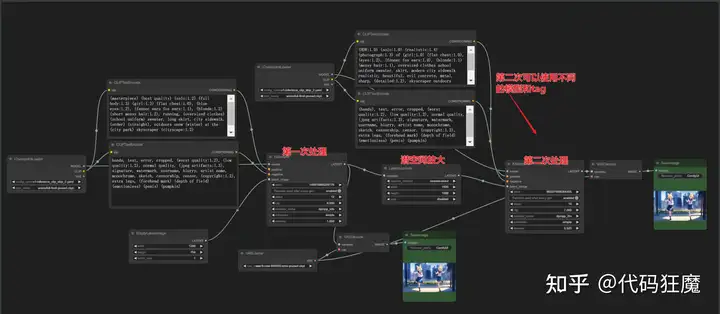
高清修复二次处理工作流:”Hires Fix” aka 2 Pass Txt2Img
注意模型选择的地方要进行选择(点开下拉框选择),不然可能导致工作流只进行一部分,解析如下
- 潜空间放大
- 像素空间放大后在编码到潜空间重绘
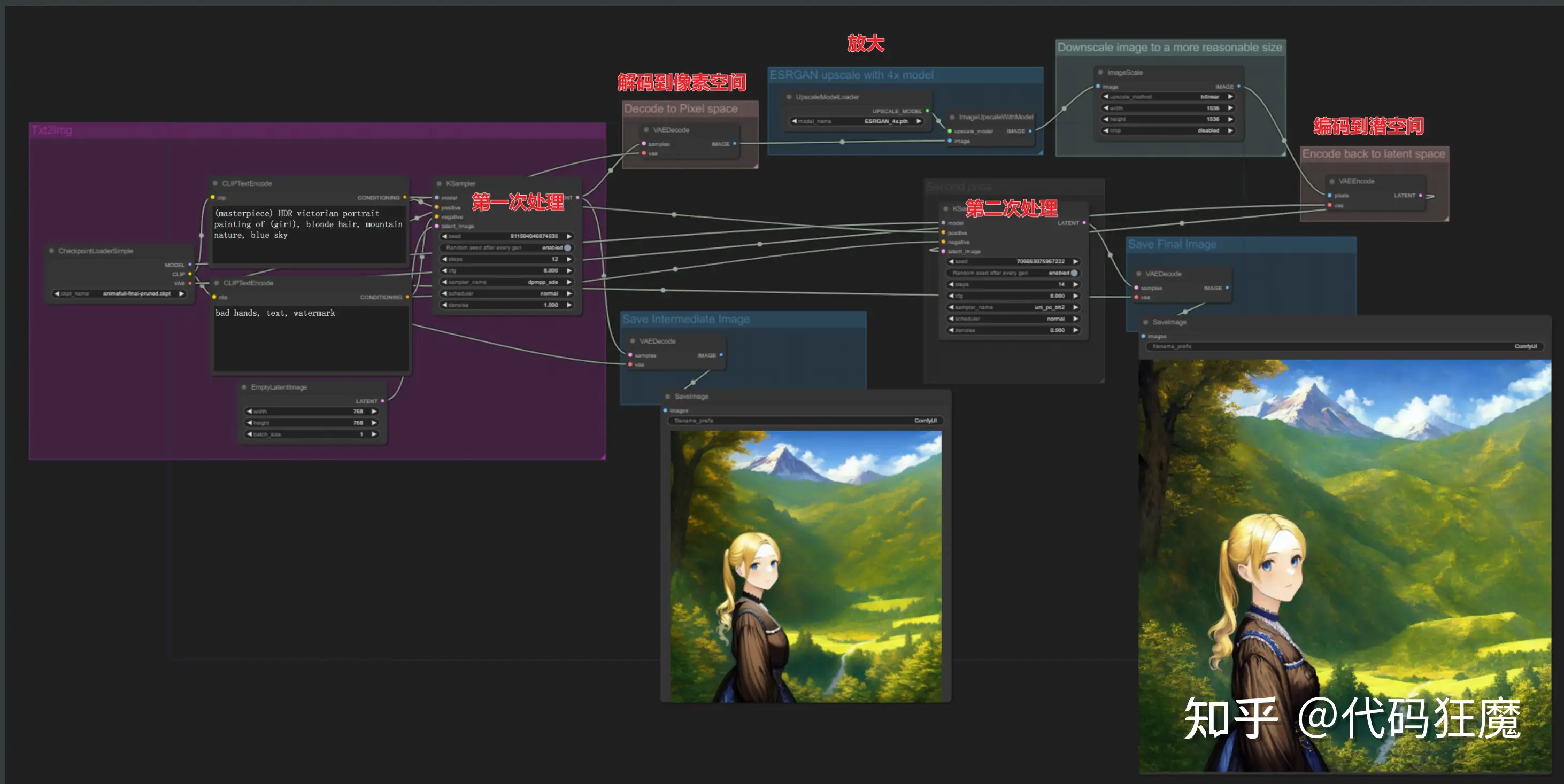
- 第二次处理使用不同的模型和tag
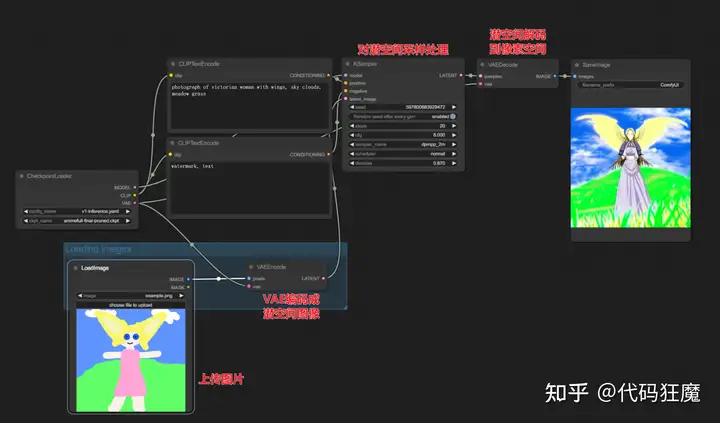
图生图Img2Img
图生图流程相对简单,直接将图片编码成潜空间后采样处理解码到像素空间,相当于用一张图片的噪声替换随机噪声
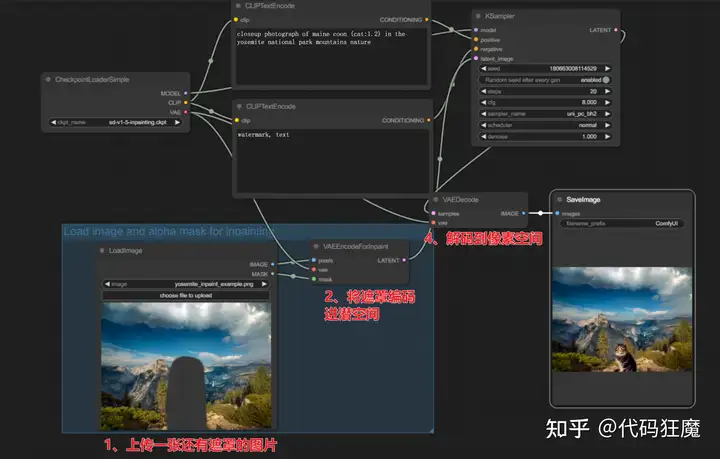
内部绘制Inpainting
- 可以理解为在图生图的基础之上将上传的图片换成了带有遮罩的图片
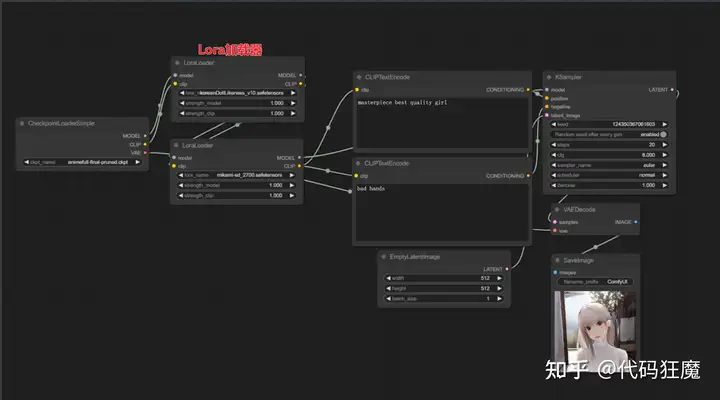
Lora
- 在模型选择与tag之间增加了Lora加载器,可以串接多个Lora
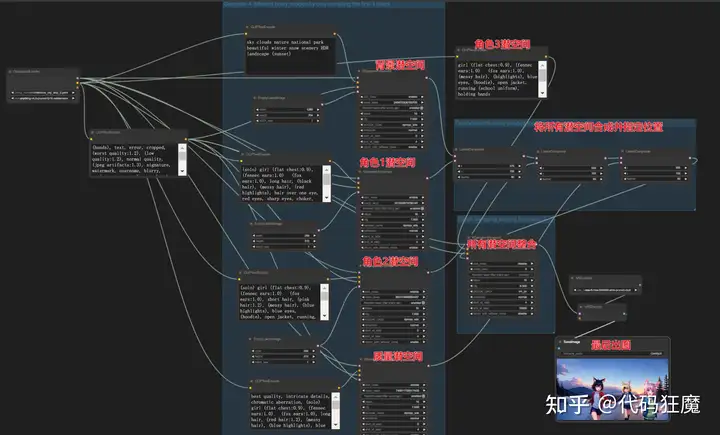
噪声图合成Noisy Latent Composition
下面看一个复杂一些的例子,下面的工作流会生成多个潜空间并整合多个潜空间,在生成最终图片,这样的效果在WebUI中需要插件才能实现。
![图片[16]-5分钟系列:5分钟学会2023年最火的AI绘画(ComfyUI节点式UI,制作专业工作流)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[17]-5分钟系列:5分钟学会2023年最火的AI绘画(ComfyUI节点式UI,制作专业工作流)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏







暂无评论内容