
目录如下

介绍及效果展示
介绍及效果展示
AI视频换脸和前面章节的AI绘图没有直接关系,但是都是AI相关的,所以归类到一起了,看一下效果,先是一张图的

以下是视频的,此处只截取了其中一帧
坤坤 + 宝强

紫霞仙子
+ 凤姐

紫霞仙子 + 一哭二闹三上不悠亚

你来的正是时候
+ 成龙大哥

你养我啊 + 宝强
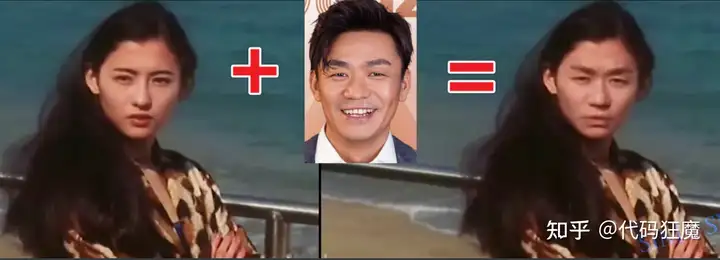
邪剑仙 + 成龙大哥

不同角度的、hhhhhh

可以看到大幅度转动头都可以替换,边缘处还是有些接缝

本次主要介绍的是SimSwap(Simple Swap),即简易的换脸,是上海交通大学和腾讯联合研发的一个框架。
- Swapping face using ONE single photo 一张图免训练换脸
- 显存要求3G以上
- 对比需要训练的换脸来说,它的效果没有那么好,但是它速度快而且免训练且只要一张照片,门槛较低,其官方仓库为:https://github.com/neuralchen/SimSwap
和DeepFaceLab相比较,效果不佳大概有两方面原因:
- 仅仅替换了五官而不是整个脸部
- 用到的脸部训练数据似乎都是欧美人的数据,不适合亚洲人的脸型
官方仓库做了免责声明
本项目仅供技术和学术使用。严禁应用于非法和不道德用途。
如果违反用户所在国家或地区的法律和道德要求,此代码库免责
另本文的免责声明如下
本文仅供娱乐、学习等使用。严禁应用于非法、不道德、商业牟利等用途。
如果违反用户所在国家或地区的法律和道德要求,本文及其作者免责!
环境准备及安装
首先安装Git、Python等,本文使用的是Python 3.10.8,然后在GitBash中执行如下命令,请注意不是PowserShell,可以参考官方的指引
官方指引使用的是conda,比较麻烦因此本文直接使用Python自带的venv环境,另外指引推荐的
torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1组合太过于久远,本文使用torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0实测也能正常工作
git clone https://github.com/neuralchen/SimSwap
cd SimSwap
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
. venv/Scripts/activate
# [可选]键入pip,果没有或者损坏等使用如下命令安装
py -m pip install --upgrade pip
# 安装依赖,此处很慢要么开T子要么配置国内代理
# 如下组合太过于久远
# pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
# 使用如下组合安装torch
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 -f https://download.pytorch.org/whl/torch_stable.html
# 安装其他包
pip install --ignore-installed imageio
pip install insightface==0.2.1 onnxruntime moviepy
#[可选]如果运行过程中报错如下,则安装numpy==1.23.5
AttributeError: module 'numpy' has no attribute 'float'.
pip install numpy==1.23.5到此Python环境就已经准备完成了,下面需要准备运行所需的模型文件,注意此处很多模型,一定按照下文描述将文件放置到对应的位置(下面中描述的位置都是以项目根目录
基础路径),否则会运行失败
1、模型文件:arcface_checkpoint
- 下载链接:https://github.com/neuralchen/SimSwap/releases/download/1.0/arcface_checkpoint.tar
- 放置位置:
arcface_model,该文件无需解压
2、模型文件:checkpoints
- 下载链接:https://github.com/neuralchen/SimSwap/releases/download/1.0/checkpoints.zip
- 放置位置:
checkpoints,该文件需解压,目录不存在需创建
3、模型文件:550000_net_G
- 下载链接:https://github.com/neuralchen/SimSwap/releases/download/512_beta/512.zip
- 放置位置:
checkpoints,该文件需解压,目录不存在需创建
4、模型文件:79999_iter
- 下载链接:https://github.com/neuralchen/SimSwap/releases/download/1.0/79999_iter.pth
- 放置位置:
parsing_model/checkpoint,该文件需解压,目录不存在需创建
5、模型文件:antelope
- 下载链接:https://sh23tw.dm.files.1drv.com/y4mmGiIkNVigkSwOKDcV3nwMJulRGhbtHdkheehR5TArc52UjudUYNXAEvKCii2O5LAmzGCGK6IfleocxuDeoKxDZkNzDRSt4ZUlEt8GlSOpCXAFEkBwaZimtWGDRbpIGpb_pz9Nq5jATBQpezBS6G_UtspWTkgrXHHxhviV2nWy8APPx134zOZrUIbkSF6xnsqzs3uZ_SEX_m9Rey0ykpx9w
- 放置位置:
insightface_func/models,该文件需解压,目录不存在需创建
如果不确认上面文件具体怎么放置,那么直接执行下面的脚本进行放置,注意在GitBash中执行,在项目目录右键打开GitBash,前提是要将以上所有文件下载好放到项目根路径的downlaod目录中,目录需先创建
mkdir downlaod
# 需将上文提到的5个文件都下载好并且放到该目录中
# 执行模型文件放置操作
mkdir arcface_model
cp downlaod/arcface_checkpoint.tar arcface_model
mkdir checkpoints
cp downlaod/checkpoints.zip checkpoints
cd checkpoints && unzip checkpoints.zip && rm -rf checkpoints.zip && cd -
cp downlaod/512.zip checkpoints
cd checkpoints && unzip 512.zip && rm -rf 512.zip && cd -
mkdir -p parsing_model/checkpoint
cp downlaod/79999_iter.pth parsing_model/checkpoint
mkdir -p insightface_func/models
cp downlaod/antelope.zip insightface_func/models
cd insightface_func/models && unzip antelope.zip && rm -rf antelope.zip && cd -
# 放置好后最后的目录结构如下
ls -lh arcface_model checkpoints parsing_model/checkpoint insightface_func/models
arcface_model:
total 732M
-rw-r--r-- 1 wx 197121 732M 4月 15 22:28 arcface_checkpoint.tar
checkpoints:
total 4.0K
drwxr-xr-x 1 wx 197121 0 11月 24 2021 512/
drwxr-xr-x 1 wx 197121 0 4月 15 22:31 people/
insightface_func/models:
total 237M
drwxr-xr-x 1 wx 197121 0 4月 15 23:20 antelope/
parsing_model/checkpoint:
total 51M
-rw-r--r-- 1 wx 197121 51M 4月 15 22:27 79999_iter.pth
至此所有环境准备完毕,下面测试一下,在venv环境中使用如下命令跑一个测试,这个测试的所有文件仓库中都已经有了
# 更换一下案列结果名称以做对比
mv output/result.jpg output/result1.jpg
# 运行测试
python test_one_image.py --isTrain false --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path crop_224/6.jpg --pic_b_path crop_224/ds.jpg --output_path output/期间有很多Waning信息,可以不用理会,整个过程如果没报错并且可以在output目录中找到刚才生成的result.jpg文件,说明整个环境是OK的,这个测试运行完的结果就是文初所展示的单张换脸

使用案列及技巧
案列一单人替换:坤坤 + 宝强
首先找到坤坤两年半自我介绍的视频素材,直接B站
B站视频下载可使用xbeibeix工具,将链接粘贴过去后输入验证码在页面上找到下载按钮会弹出下载教学
视频准备好以后准备ffmpeg工具用于处理视频,本文使用图形化视频剪辑工具,不太方便而且不能批量处理,如果需要高级的操作可以使用图形化视频剪辑工具,ffmpeg安装如下
下载好ZIP包以后放置到系统的环境变量
目录,在命令行输入ffmpeg -version有版本信息提示说明安装成功,接下来就是处理视频。视频处理的思路是先找到原素材中需要的片段,然后裁剪适合的画面,这部分操作使用ffmpeg命令如下
- 找到素材中需要的片段,比如从6秒开始到16秒结束的位置是需要的,
00:00:06表示从6秒开始,`00:00:10表示持续10秒,即16秒结束的位置,完成以后ckx_crop.mp4即是我们需要的片段
ffmpeg -ss 00:00:06 -t 00:00:10 -i ckx_in.mp4 ckx_clip.mp4- [可选]由于现在画面中坤坤的位置比较靠中间,最后我们需要的效果是做换脸前和换脸后合在一个视频中做对比,因此需要将原视频中不需要的两边空白部分做裁剪,只留下中间坤坤的部分,可以使用如下命令
ffmpeg -i ckx_clip.mp4 -filter:v "crop=in_w/2:in_h:in_w/2/2:0" ckx_crop.mp4以上命令可以将画面进行裁剪,如下图所示

crop=in_w/2:in_h:in_w/2/2:0参数表示的含义是从坐标(in_w/2/2,0)开始算,需要in_w/2个像素的宽度,in_h个像素的高度,所以整个画面裁剪后就是下图中黄色的区域
in_w:表示输入视频的宽度in_h:表示输入视频的高度
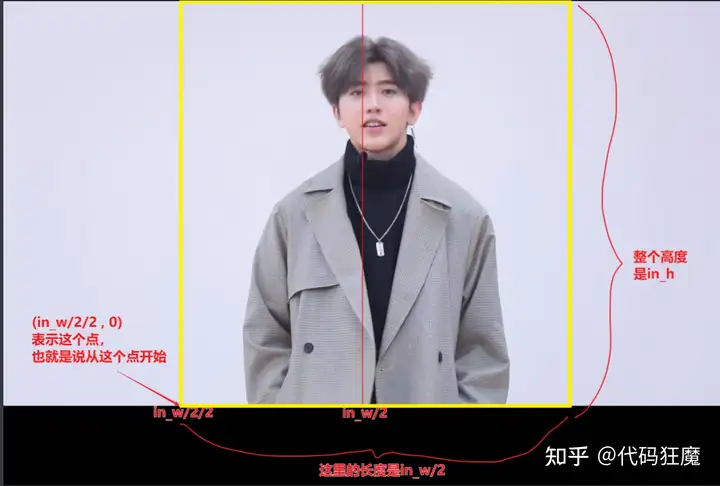
当然如果还想让坤坤更大一些,也就是两边的白边更少一些可以将起点往右挪动一百个像素,需要的宽度再两边各减一百即两百,表达式如有所示(注意后两个参数表示起点,前两个参数表示需要的宽和高),crop=in_w/2-200:in_h:in_w/2/2+100:0,这样坤坤就会更大一些,如下所示,此处画面裁剪根据自己的需要操作

最后其实片段和裁剪可以一起操作,不用分开,如下表示从6秒开始需要10秒并且裁剪画面中间的部分
ffmpeg -ss 00:00:06 -t 00:00:10 -i ckx_org.mp4 -filter:v "crop=in_w/2:in_h:in_w/2/2:0" ckx_crop.mp4此时需要的素材就已经准备好了,接下来准备一张人脸照片,对照片的选择是有要求的
- 尽量是正面,脸部无遮挡
- 表情不要过于夸张
- 颜色尽量和原图接近,不要差异过大
- 图像尺寸尽量清晰,不要太糊
- 背景尽量单一不要太过于杂乱
根据以上要求找到了宝强的照片

将上面的素材放到项目目录中(如output/cxk)并在项目根目录中执行python命令
# 指定基础路径
bp=./output/cxk
# 指定宝强照片
pic_a_path=$bp/wangbaoqiang.png
# 坤坤裁剪后的视频
video_path=$bp/cxk_crop.mp4
# 输出的视频
output_path=$bp/cxk_out.mp4
python test_video_swapsingle.py --crop_size 224 --use_mask --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path $pic_a_path --video_path $video_path --output_path $output_path --temp_path ./temp_results
如果能看到下面的进度条说明执行成功,正在换脸中
-------------- End ----------------
input mean and std: 127.5 127.5
find model: ./insightface_func/modelsantelopeglintr100.onnx recognition
find model: ./insightface_func/modelsantelopescrfd_10g_bnkps.onnx detection
set det-size: (640, 640)
(142, 366, 4)
23%|████████████████████ | 139/594 [02:09<07:13, 1.05it/s]最后预料之中cxk_out.mp4包含了换脸的视频,我们要将换脸前和换脸后的视频做一个对比,换脸前的在左边,换脸后的在右边。执行如下命令
ffmpeg -i cxk_crop.mp4 -i cxk_crop.mp4 -filter_complex hstack cxk.mp4最后打开cxk.mp4文件可以看到效果和文初展示的一样,至此坤坤换脸完成!

案列二指定人替换:邪剑仙 + 成龙大哥
素材准备及处理就不说了,此处和案例一相比有个区别是需要指定目标替换人脸,因为原素材中有多张人脸,因此需要指定一张,在原素材中截取一张目标人脸,和找图片是一样的规则,尽量正面、清晰、不遮挡,如下截取的一张邪剑仙的图片

在找一张成龙的图片

最后使用如下命令,和以上的区别是此处参数多了一个指定目标人脸的参数
bp=./output/xjx
# 指定的邪剑仙的照片
pic_specific_path=$bp/specific.png
pic_a_path=$bp/cl.jpg
video_path=$bp/xjx_crop.mp4
output_path=$bp/xjx_out.mp4
python test_video_swapspecific.py --crop_size 224 --use_mask --pic_specific_path $pic_specific_path --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path $pic_a_path --video_path $video_path --output_path $output_path --temp_path ./temp_results
最后结果如文初所示:

另外还有其他的命令可以参考,详情可参考仓库使用指引:https://github.com/neuralchen/SimSwap/blob/main/docs/guidance/usage.md
- 替换所有人脸
python test_video_swapmulti.py --crop_size 224 --use_mask --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path ./demo_file/Iron_man.jpg --video_path ./demo_file/multi_people_1080p.mp4 --output_path ./output/multi_test_swapmulti.mp4 --temp_path ./temp_results - 替换多个指定人脸
python test_video_swap_multispecific.py --crop_size 224 --use_mask --name people --Arc_path arcface_model/arcface_checkpoint.tar --video_path ./demo_file/multi_people_1080p.mp4 --output_path ./output/multi_test_multispecific.mp4 --temp_path ./temp_results --multisepcific_dir ./demo_file/multispecific
# multispecific目录命名规则
├── DST_01.jpg(png)
└── DST_02.jpg(png)
└──...
└── SRC_01.jpg(png)
└── SRC_02.jpg(png)
└──...
工作流脚本
其实工作流就是上文所描述的过程,下面将上文所描述的整个过程使用脚本一键化进行,脚本内容如下
# 坤坤+宝强调用示例(原视频只有一张人脸,不指定)
# sh faceswap.sh ./output/cxk cxk_download.mp4 00:00:00 00:00:05 true 50 "" wangbaoqiang.png true
# 你养我啊+成功调用示例(指定人脸)
# sh faceswap.sh ./output/nywa nywa_download.mp4 00:00:00 00:00:20 false 0 specific.png luoyufeng.png true
# 基本路径
base_path=$1
# 原文件
src_file=$2
# 开始时间
start_time=$3
# 持续时间
duration_time=$4
# 是否需要裁剪画面
crop=$5
# 裁剪画面挪动的像素
crop_pix=$6
# 指定视频中的目标替换人脸
specific_file=$7
# 替换后的人脸
pic_a_file=$8
# 是否合并对比视频
side_by_side=$9
org_file="${src_file%.*}_org.mp4"
output_file="${src_file%.*}_out.mp4"
merge_file="${src_file%.*}_merge.mp4"
. ./venv/Scripts/activate
[[ $? == 0 ]] && echo "进入Python venv环境成功!"
sleep 1
rm -rf $base_path/$org_file $base_path/$output_file $base_path/$merge_file
echo "裁剪后的文件名:$org_file 处理后的文件名:$output_file 合并对比的文件名:$merge_file"
[[ -n "$crop" ]] && {
echo "进行剪辑中,从$start_time 开始剪辑,持续时间$duration_time,检测到需要裁剪,且裁剪往中间挪动的像素为:$crop_pix"
ffmpeg -ss $start_time -t $duration_time
-i $base_path/$src_file
-filter:v "crop=in_w/2-2*$crop_pix:in_h:in_w/2/2+$crop_pix:0"
$base_path/$org_file
} || {
echo "进行剪辑中,从$start_time 开始剪辑,持续时间$duration_time"
ffmpeg -ss $start_time -t $duration_time
-i $base_path/$src_file $base_path/$org_file
}
[[ $? != 0 ]] && echo "剪辑失败!"
[[ -n "$specific_file" ]] && {
echo "指定了目标人脸文件$specific_file,全部参数如下,进行AI换脸中..."
echo "pic_specific_path:$base_path/$specific_file"
echo "pic_a_path:$base_path/$pic_a_file"
echo "video_path:$base_path/$org_file"
echo "output_path:$base_path/$output_file"
python test_video_swapspecific.py --crop_size 224
--use_mask --pic_specific_path $base_path/$specific_file
--name people --Arc_path arcface_model/arcface_checkpoint.tar
--pic_a_path $base_path/$pic_a_file
--video_path $base_path/$org_file
--output_path $base_path/$output_file
--temp_path ./temp_results
} || {
echo "全部参数如下,进行AI换脸中..."
echo "pic_a_path:$base_path/$pic_a_file"
echo "video_path:$base_path/$org_file"
echo "output_path:$base_path/$output_file"
python test_video_swapsingle.py --crop_size 224
--use_mask --name people --Arc_path
arcface_model/arcface_checkpoint.tar
--pic_a_path $base_path/$pic_a_file
--video_path $base_path/$org_file
--output_path $base_path/$output_file
--temp_path ./temp_results
}
[[ ! -f $base_path/$output_file ]] && {
echo "换脸失败!"
rm -rf $base_path/$org_file $base_path/$output_file $base_path/$merge_file
exit 1
}
[[ -n "$side_by_side" ]] && {
echo "检测到需要合并对比视频,合并进行中..."
echo "换脸前文件:$base_path/$org_file"
echo "换脸后文件:$base_path/$output_file"
echo "输出文件:$base_path/$merge_file"
ffmpeg -i $base_path/$org_file -i $base_path/$output_file
-filter_complex hstack $base_path/$merge_file
}
[[ $? != 0 ]] && echo "合并失败!"
echo "成功!输出文件为:$base_path/$merge_file"
将上述内容复制下来保存到项目根路径下,文件名为faceswap.sh,在根路径下右键GitBash,以上面坤坤的案例为例,准备好文件
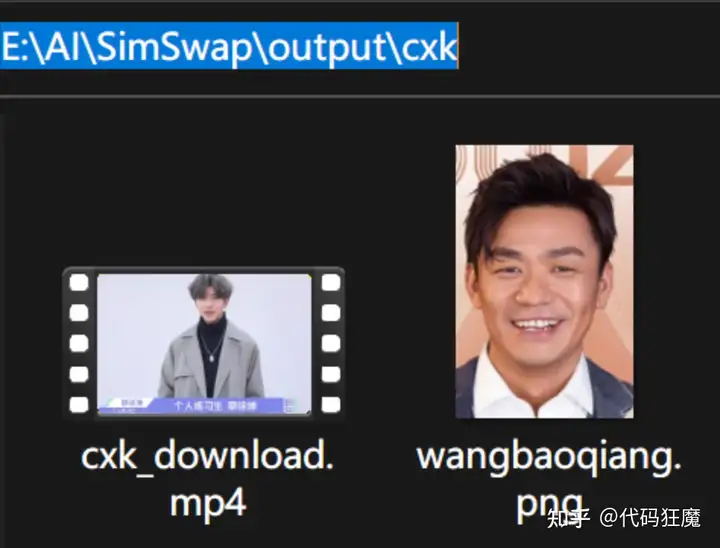
然后调用如下,其含义是说将cxk_download.mp4文件的前5s截取出来,然后裁剪一下,剩下中间人物的部分,再使用wangbaoqiang.png进行换脸,换脸后需要合并成对比文件
sh faceswap.sh
./output/cxk
cxk_download.mp4 00:00:00 00:00:05 true 50 ""
wangbaoqiang.png true运行成功后会有如下提示
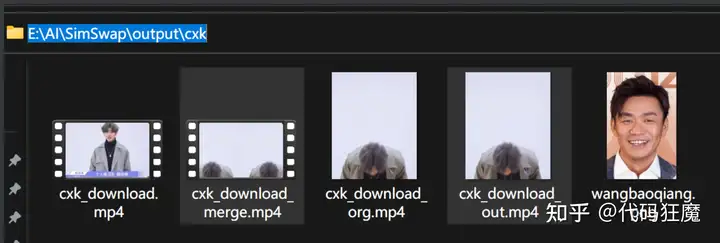
成功!输出文件为:./output/cxk/cxk_download_merge.mp4运行完成以后生成结果如下,其中
cxk_download_out.mp4是换脸后的视频文件cxk_download_merge.mp4是换脸前后的对比视频
下面再来一个案列,是指定人脸的案列,因为原视频中有多张人脸,准备的素材如下
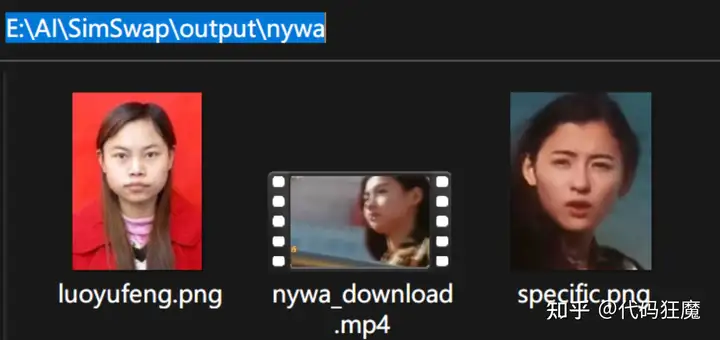
调用命令如下,具体含义就不再赘述了
sh faceswap.sh
./output/nywa
nywa_download.mp4 00:00:00 00:00:10 false 0
specific.png luoyufeng.png true完成以后的结果如下
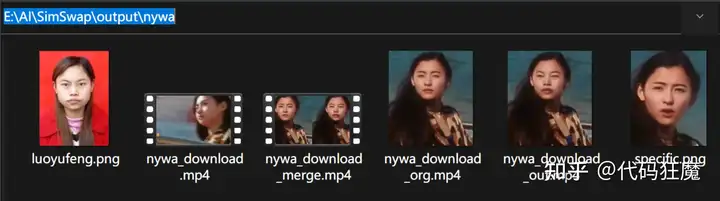
效果如下,hhhhh

奉上案列中换脸的视频


![图片[27]-5分钟系列:5分钟学会2023年最火的AI视频换脸(含案列讲解及素材获取,全网最强教学)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[28]-5分钟系列:5分钟学会2023年最火的AI视频换脸(含案列讲解及素材获取,全网最强教学)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏








暂无评论内容