
先来看一组小姐姐,激发你的学习欲望!
模型:dalcefo_painting













===============2023-03-10更新===============





这些小姐姐除了很漂亮之外她们还有一个特点:她们在现实中并不存在,是电脑AI生成的!AI 就像16 年打败李世石进军围棋行业一样,开始进军艺术界了,下面就来看看如何在电脑上进行AI作画,现在AI的发展之快,适当的掌握技巧和一些概念后,每个人都能成为AI艺术家,实现想看美女自己画的宏伟目标!
介绍
要介绍的工具叫做Stable Diffusion,一句话描述:Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,也有热心网友开发了WEB页面易于使用,叫做stable-diffusion-webui
安装
配置要求
要顺利运行stable-diffusion-webui和模型, 需要足够大的显存,最低配置4GB显存,基本配置6GB显存,推荐配置12GB显存。 当然内存也不能太小,最好大于16GB,总之内存越大越好,笔者显卡为NVIDIA GeForce GTX 1050 Ti ( 4 GB / NVIDIA ),这个上古显卡跑AI绘画着实比较吃力,但也能将就用。
另外注意以下链接如遇打不开请自带梯子。
1、安装Python 3.10.6
WIndows电脑使用如下链接点击安装即可,安装的时候记得将环境变量勾上,安装完成后Win+R,输入cmd回车后在命令行窗口输入python再次回车能正确显示版本即可,如果电脑上有多个python版本,不想改环境变量也可以,在stable-diffusion-webui运行前可以手动指定Python的路径
https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
2、下载stable-diffusion-webui
可以通过git clone的方式或者下载压缩包的方式从github上下载源文件,如下为项目地址
https://github.com/AUTOMATIC1111/stable-diffusion-webui
3、下载权重文件sd-v1-4.ckpt
运行必须的权重文件,4G左右,可以去hugging face
下载后放到models/Stable-diffusion目录下
https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
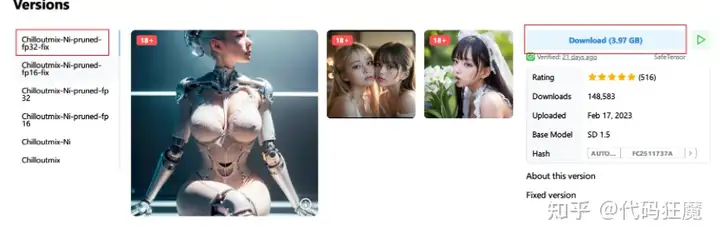
4、下载本文需要的模型文件,主要用于真人风格图像绘制
chilloutmix_NiPrunedFp32Fix.safetensors
可以去C站下载,3.97G,下载完成后放到models/Stable-diffusion目录下
https://civitai.com/models/6424/chilloutmix
5、启动应用
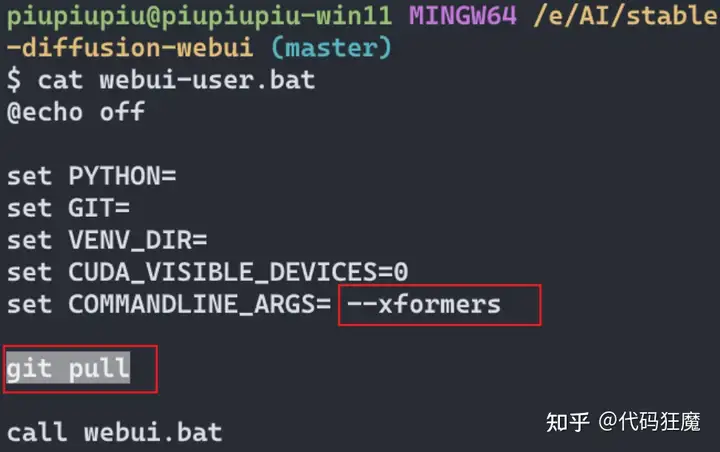
编辑根目录下的webui-user.bat文件,添加如下参数
@echo off
:: 手动设置Python环境,如果不设置,使用环境变量的Python环境
set PYTHON=
set GIT=
set VENV_DIR=
set CUDA_VISIBLE_DEVICES=1
set COMMANDLINE_ARGS= --xformers --medvram
call webui.bat
注意set COMMANDLINE_ARGS= --xformers --medvram参数很关键,在笔者上古显卡1050ti
中,必须开--medvram才能勉强跑一些大图,不设置经常爆显存!它的意思是说是使用中等的显存,显存相关说明可参考原文
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Troubleshooting
Low VRAM Video-cards
When running on video cards with a low amount of VRAM (<=4GB), out of memory errors may arise. Various optimizations may be enabled through command line arguments, sacrificing some/a lot of speed in favor of using less VRAM:
- If you have 4GB VRAM and want to make 512×512 (or maybe up to 640×640) images, use
--medvram. - If you have 4GB VRAM and want to make 512×512 images, but you get an out of memory error with
--medvram, use--lowvram --always-batch-cond-uncondinstead. - If you have 4GB VRAM and want to make images larger than you can with
--medvram, use--lowvram.
--xformers表示使用xformers,可以提高绘制速度,更多命令行参数可参考原文:
第一次启动需要下载相关依赖文件,大概会持续半个小时左右,主要是torch==1.13.1+cu117大概是2.3GB左右,以下为启动成功后的一些输出(非第一次,第一次要下载依赖,输出会更多一些)
PS F:AIstable-diffusion-webui> .webui-user.bat
venv "F:AIstable-diffusion-webuivenvScriptsPython.exe"
Python 3.10.8 (tags/v3.10.8:aaaf517, Oct 11 2022, 16:50:30) [MSC v.1933 64 bit (AMD64)]
Commit hash: 0cc0ee1bcb4c24a8c9715f66cede06601bfc00c8
Installing requirements for Web UI
Launching Web UI with arguments: --xformers
Loading weights [fc2511737a] from F:AIstable-diffusion-webuimodelsStable-diffusionchilloutmix_NiPrunedFp32Fix.safetensors
Creating model from config: F:AIstable-diffusion-webuiconfigsv1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying xformers cross attention optimization.
Textual inversion embeddings loaded(0):
Model loaded in 6.6s (create model: 0.6s, apply weights to model: 1.0s, apply half(): 0.6s, move model to device: 3.0s, load textual inversion embeddings: 1.3s).
Running on local URL: http://127.0.0.1:7860
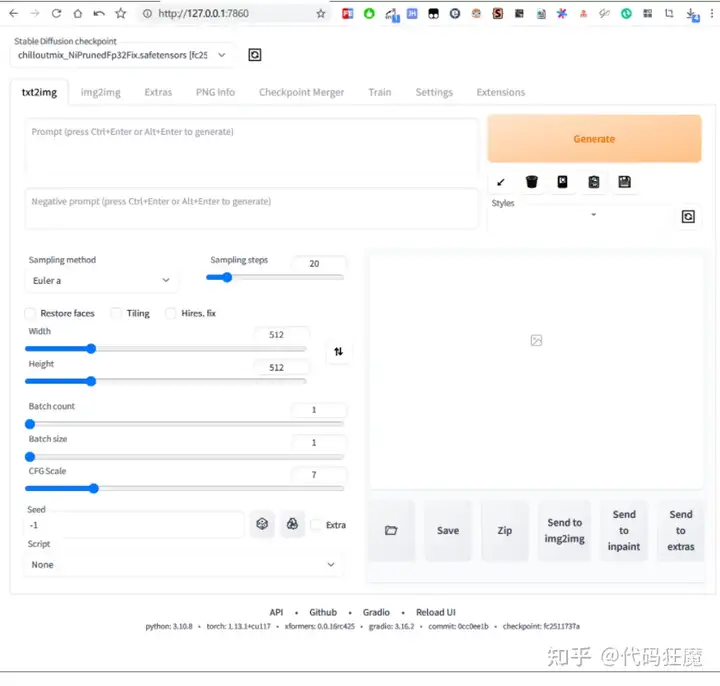
To create a public link, set `share=True` in `launch()`.此时访问 http://127.0.0.1:7860就能看到stable diffusion的页面,如下所示
几个概念
在绘图之前,有几个概念需要了解一下,首先是C站
- C站:即Civitai,是AI艺术生成社区唯一的模型共享中心,里面的图片都是AI绘制的
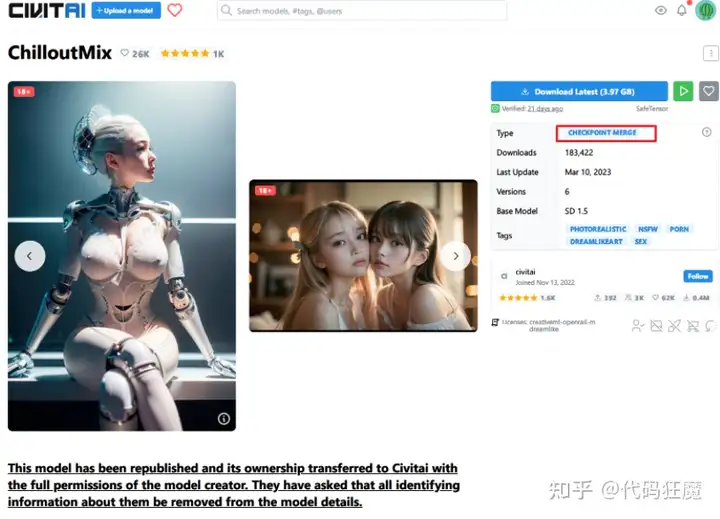
- CHECKPOINT:可以理解为是一种模型的格式,这种格式叫CHECKPOINT,这种文件一般比较大,动辄数GB,比如最近大火的ChilloutMix,它是一种CHECKPOINT,也是本文使用的生成真人图像的模型
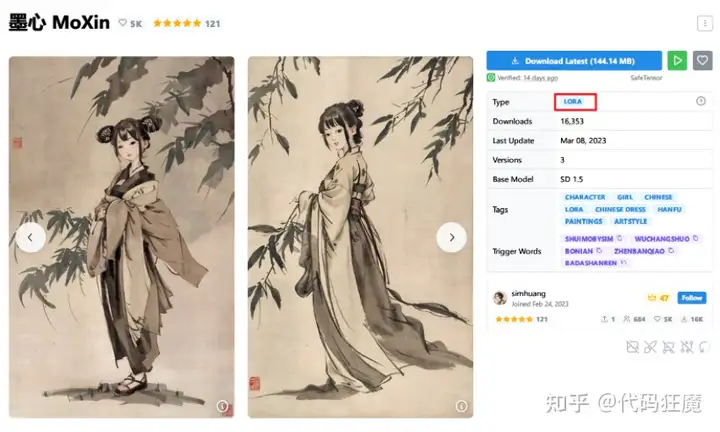
- LORA:可以理解成基于模型的微调,使用了某种LORA那么风格就趋近于它,LORA文件比较小,一般是几百MB,如下为古风的LORA示例,本文中我们没用到LORA
文生图
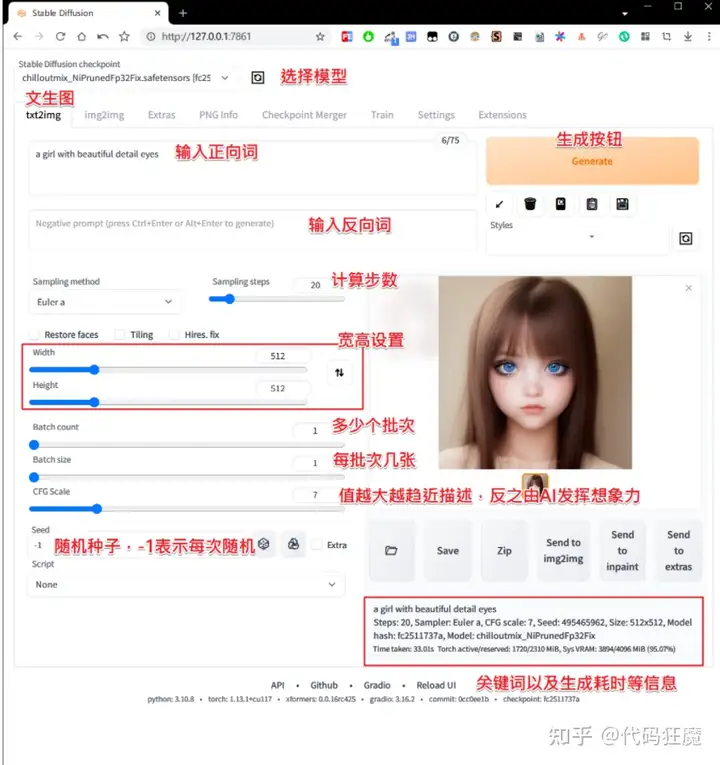
了解了以上几个基本概念以后,现在来进行图像绘制,本文主要介绍文生图的模式,即第一个tab页text2img,可以输入一些promot(提示词),如下所示,当然输入的提示词越详细生成的图越准确,比如,输入
a girl with beautiful detail eyes生成如下所示,当然这离我们的漂亮大姐姐还很远,我们需要输入更多更加细节的描述,下图中可以看到,512×512分辨率下,20个循环用了33秒
下面看看如何画出的大姐姐,去C站随便找一张图,点进去后在右下角可以看到详细的提示词信息,点击右下角拷贝提示词信息
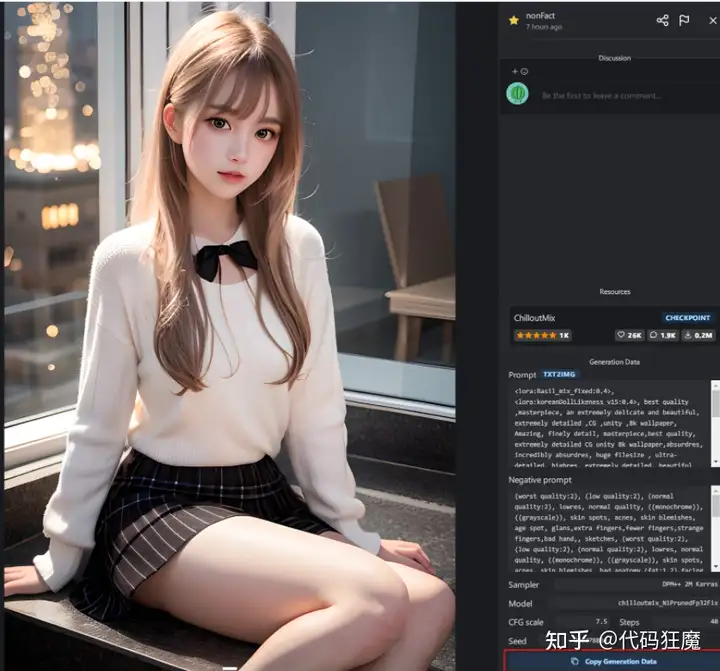
粘贴到WEB页面后点击小三角自动解析所有参数,再次点击黄色Generate生成图片
即可画出类似的图片,因为别人用了LORA本地没有,另外由于显卡算力、内存使用情况等不同画出的图可能各不相同,如下为命令行提示信息

最终画出的图如下所示,人物动作一致,服装头发和背景不太相同,可以一批次多出几个图进行挑选

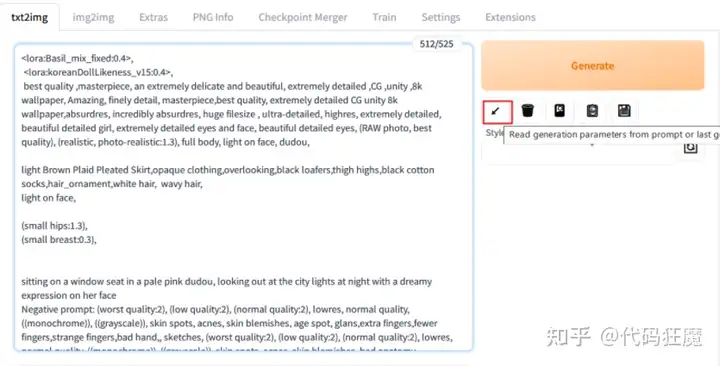
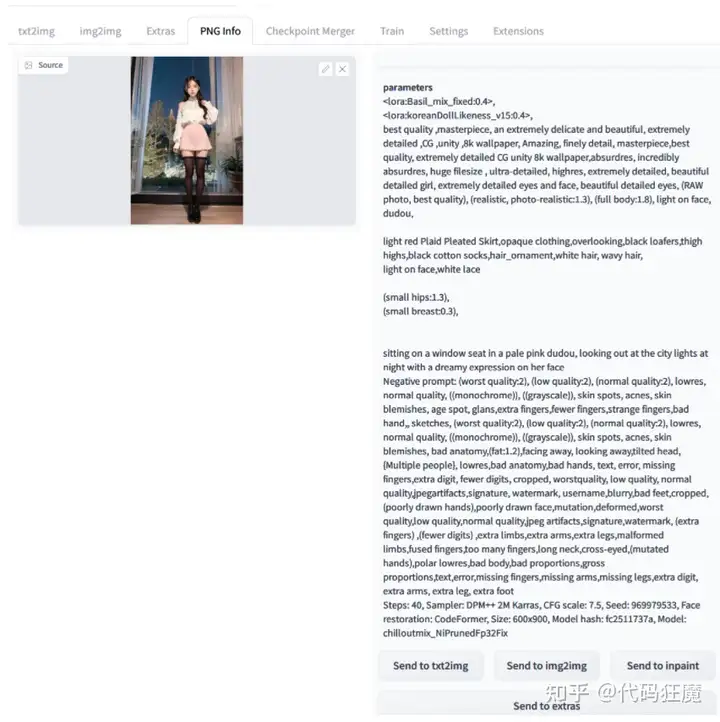
另外也可以将生成的图放到PNG Info,可以解析出原始参数,点击Send】 to text2img就可以将参数到文生图中
下面是一些其他生成的图,除了关键词,分辨率也是会影响出图的,参数:
<lora:Basil_mix_fixed:0.4>,
<lora:koreanDollLikeness_v15:0.4>,
best quality ,masterpiece, an extremely delicate and beautiful, extremely detailed ,CG ,unity ,8k wallpaper, Amazing, finely detail, masterpiece,best quality, extremely detailed CG unity 8k wallpaper,absurdres, incredibly absurdres, huge filesize , ultra-detailed, highres, extremely detailed, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, (RAW photo, best quality), (realistic, photo-realistic:1.3), full body, light on face, dudou,
light Brown Plaid Pleated Skirt,opaque clothing,overlooking,black loafers,thigh highs,black cotton socks,hair_ornament,white hair, wavy hair,
light on face,
(small hips:1.3),
(small breast:0.3),
sitting on a window seat in a pale pink dudou, looking out at the city lights at night with a dreamy expression on her face
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand,, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, bad anatomy,(fat:1.2),facing away, looking away,tilted head, {Multiple people}, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet,cropped,(poorly drawn hands),poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark, (extra fingers) ,(fewer digits) ,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,(mutated hands),polar lowres,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7.5, Seed: 145578363, Face restoration: CodeFormer, Size: 600x900, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix后面很有很多可以值的讲的,比如
- 关键词怎么写?有什么规范或者语法?
- 多种不同模型加上不同的LORA能出啥样效果的图?
- 不同显卡、不同算力、不同显存,市面上常见的显卡到底出图性能咋样?
- 图生图如何使用?换装换发型如何操作?
- ControlNet如何使用?
- 模型怎么训练?如何训练自己的模型?
当然每个点展开又是一大篇,后续有时间精力在研究,另外为啥全是妹子?因为训练模型的都是一群宅男和LSP(笑~!
注:文中提到的C站和huggingface均需要科学(魔法)上网才能正常访问。
![图片[50]-5分钟系列:5分钟学会2023世界顶级AI绘画神器Stable Diffusion(入门篇)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/wxpay.png) 微信赞赏
微信赞赏![图片[51]-5分钟系列:5分钟学会2023世界顶级AI绘画神器Stable Diffusion(入门篇)-AIGC-AI绘画部落](http://sdbbs.vvipblog.net/wp-content/uploads/2024/09/zfbpay.png) 支付宝赞赏
支付宝赞赏








暂无评论内容